
Agile Cambridge 2023
Last week, I spent a few days at Agile Cambridge. I’ve been to this conference once before back in 2014, where I gave a talk on whether agile can work for off-the-shelf software. I was also speaking this year, but about “Tracking the Unmeasurable with OKRs”. Overall, it was an enjoyable conference as it gave me time away from code, and enough headspace to think about the processes involved in writing software without the details of the tech used to do it.
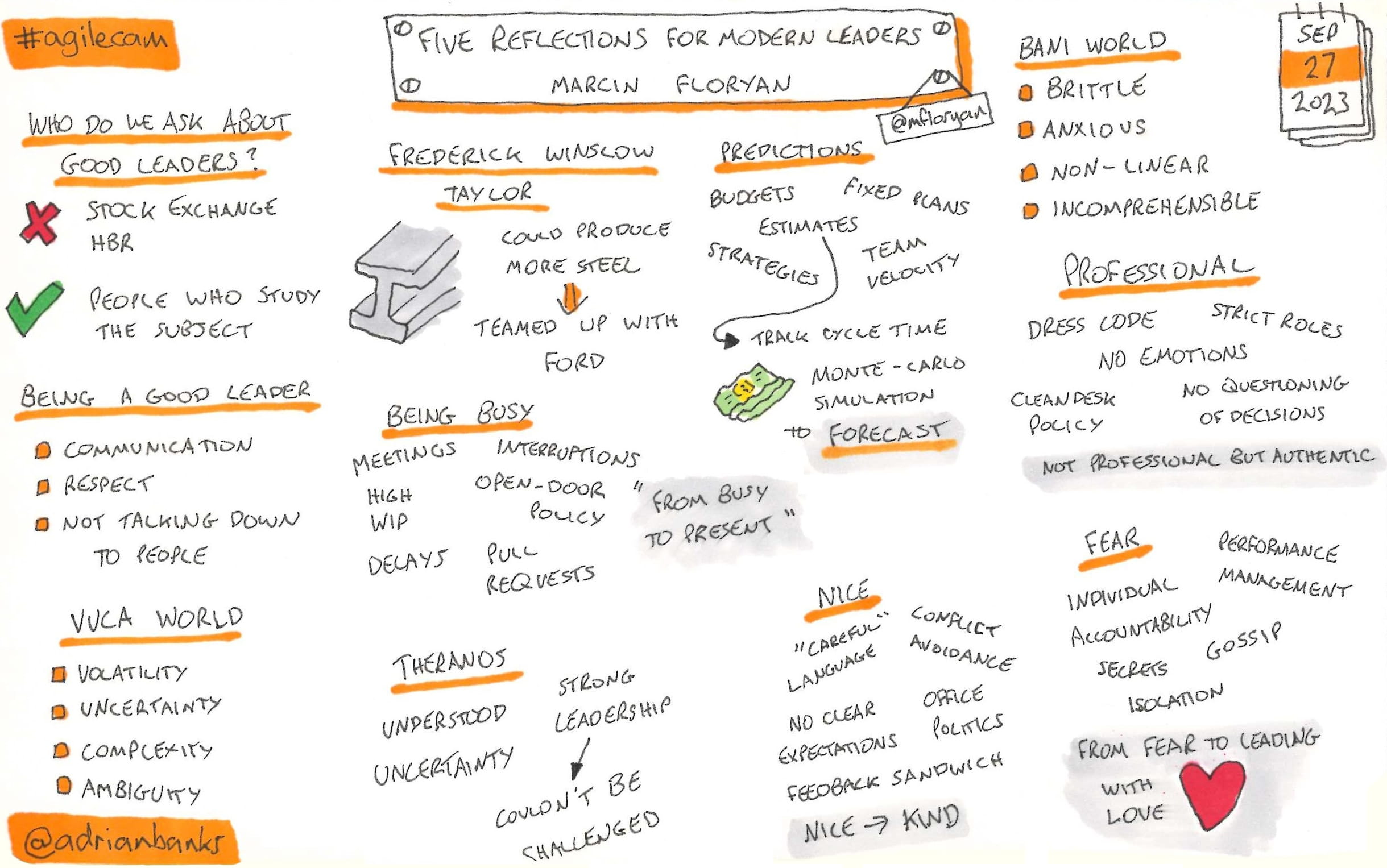
Five reflections for modern leaders
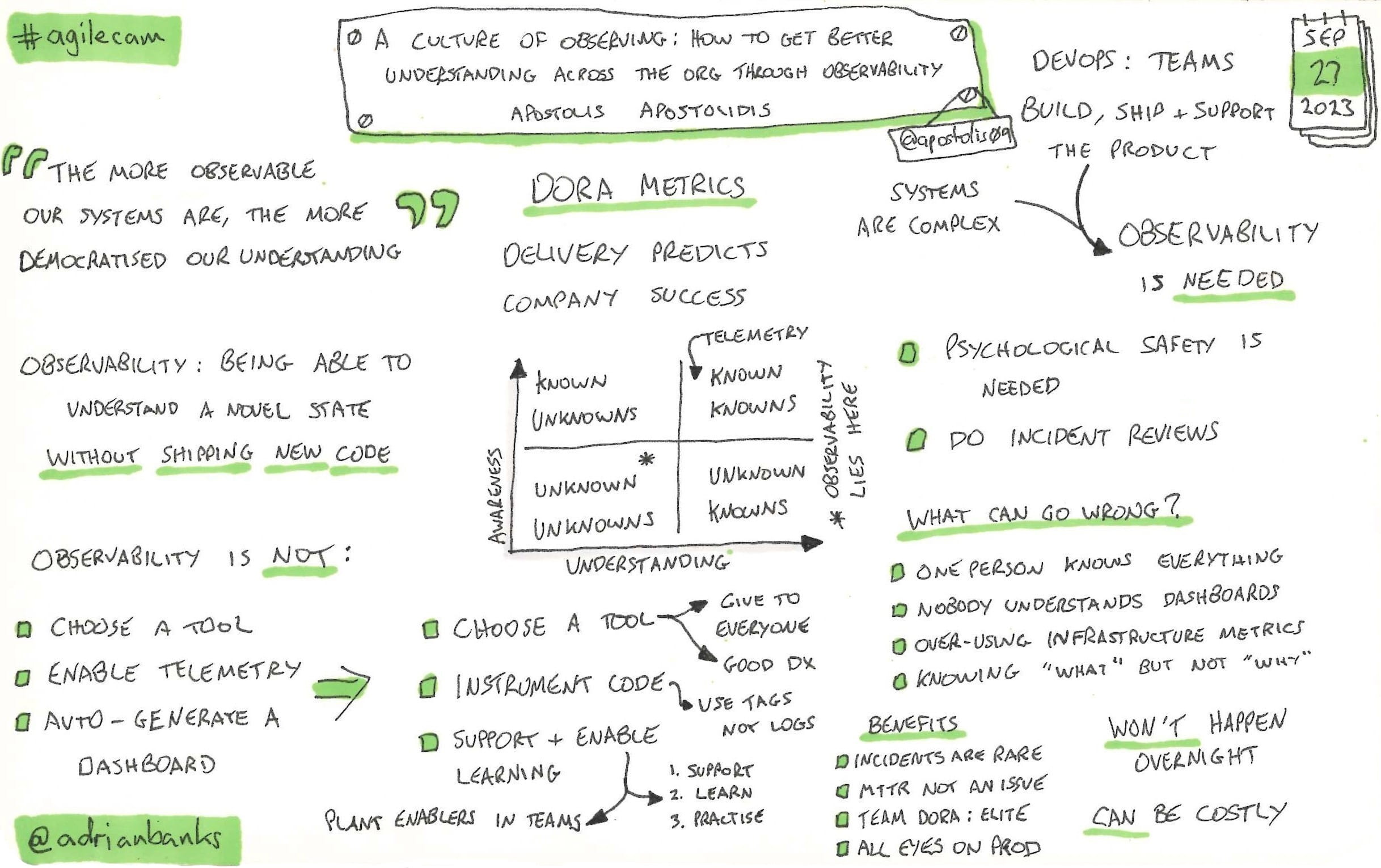
A culture of observing: how to get better understanding across the org through observability
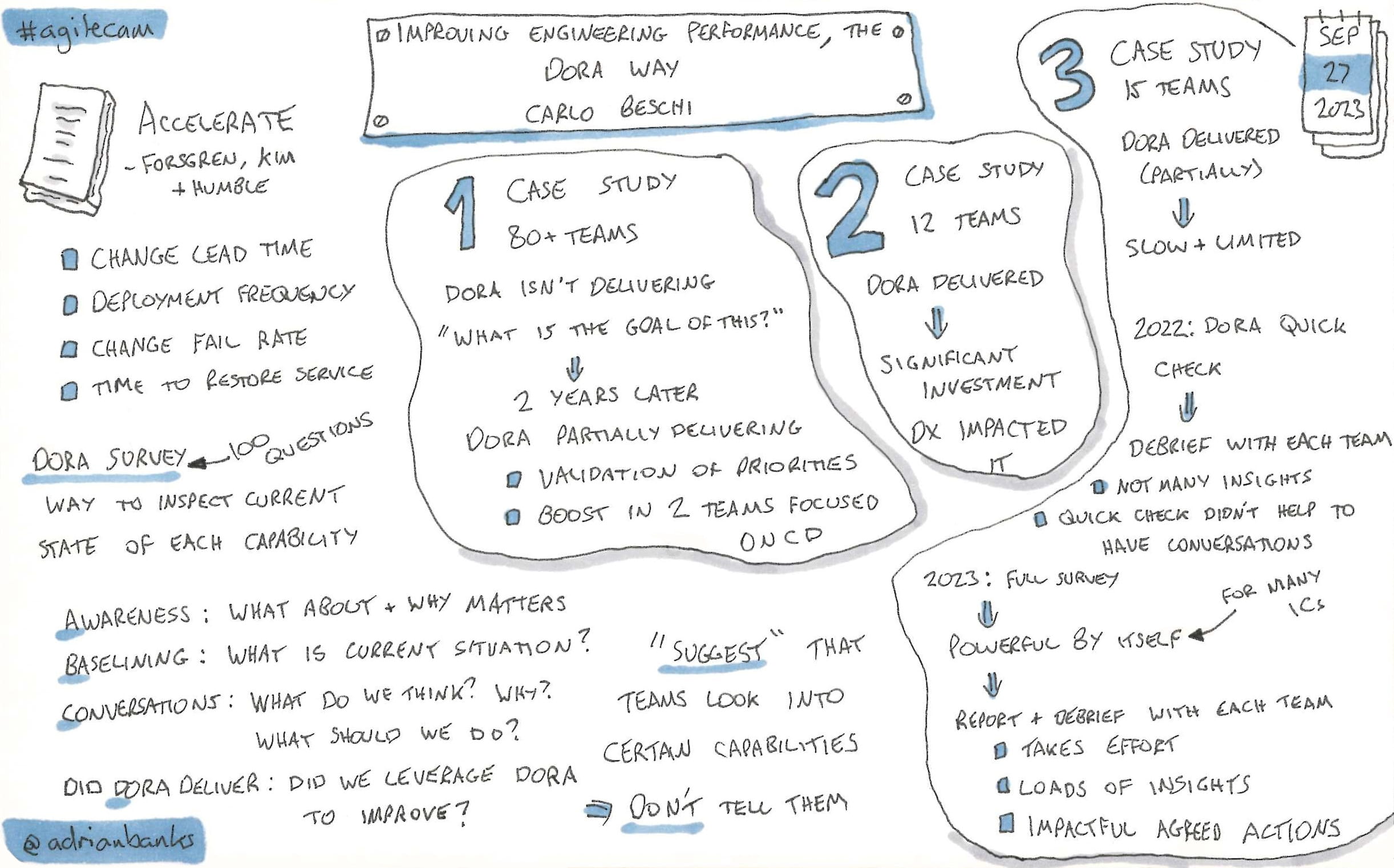
Improving engineering performance, the DORA way
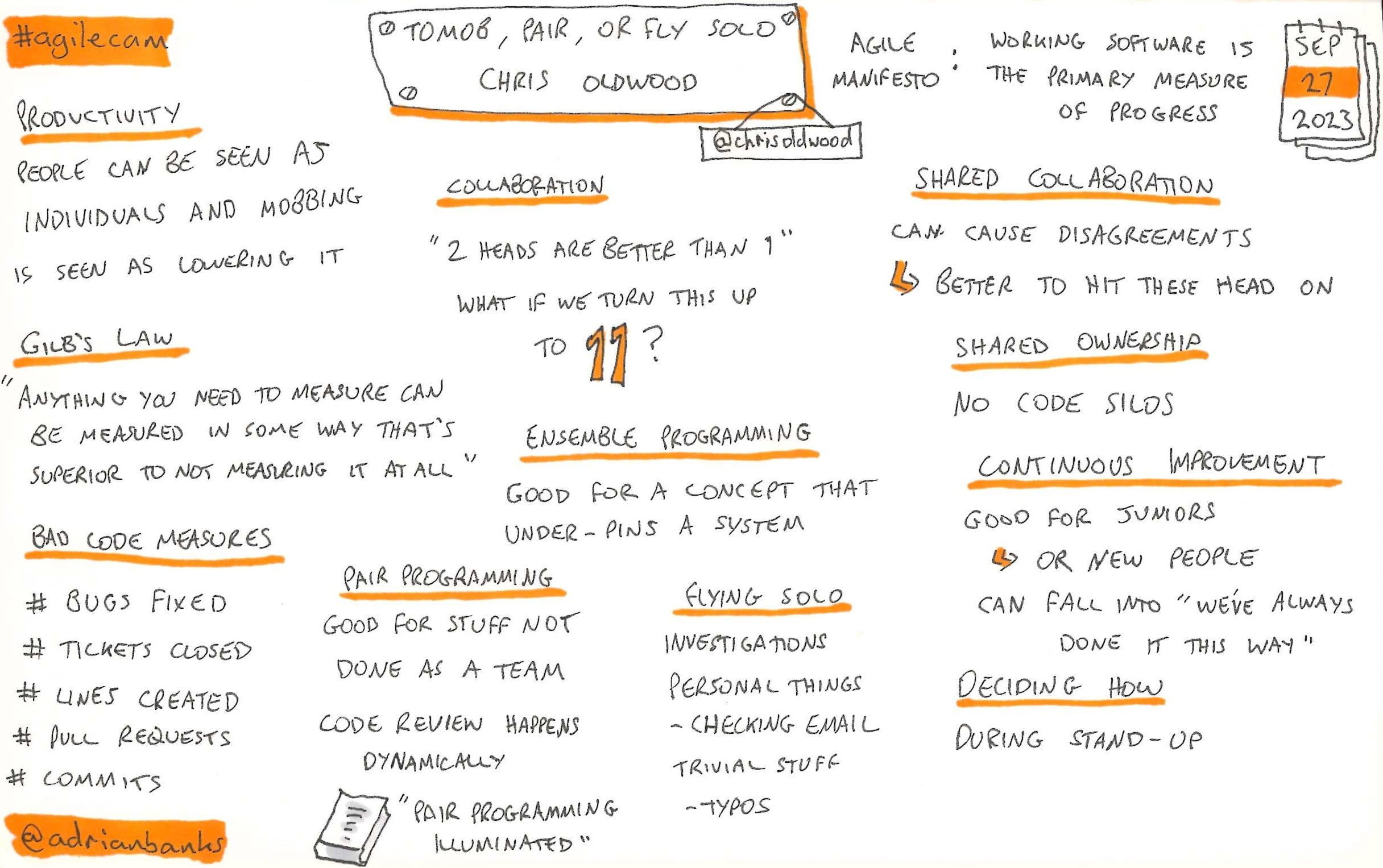
To mob, pair, or fly solo?
A game of patterns
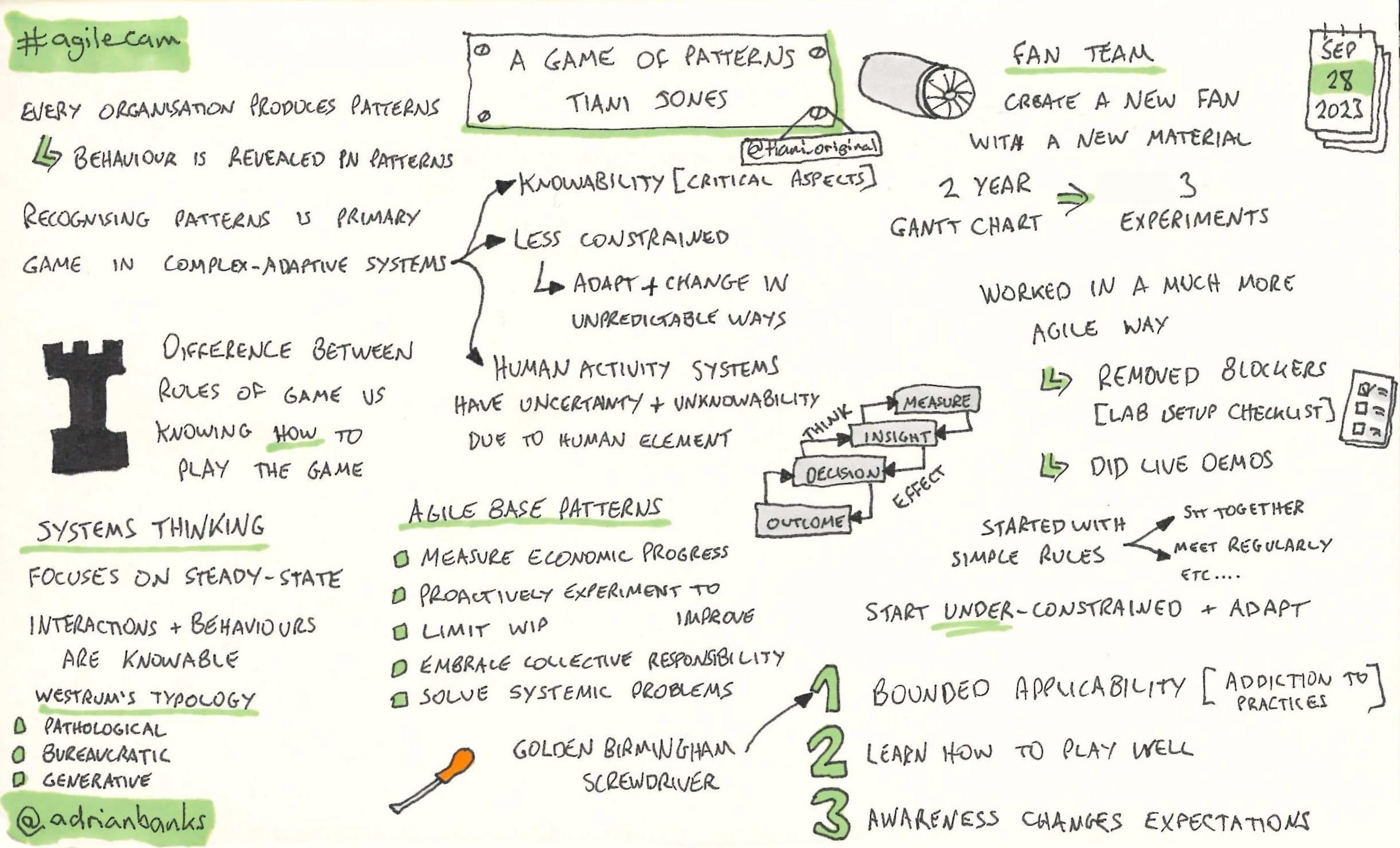
Empower your master builders with strategic context
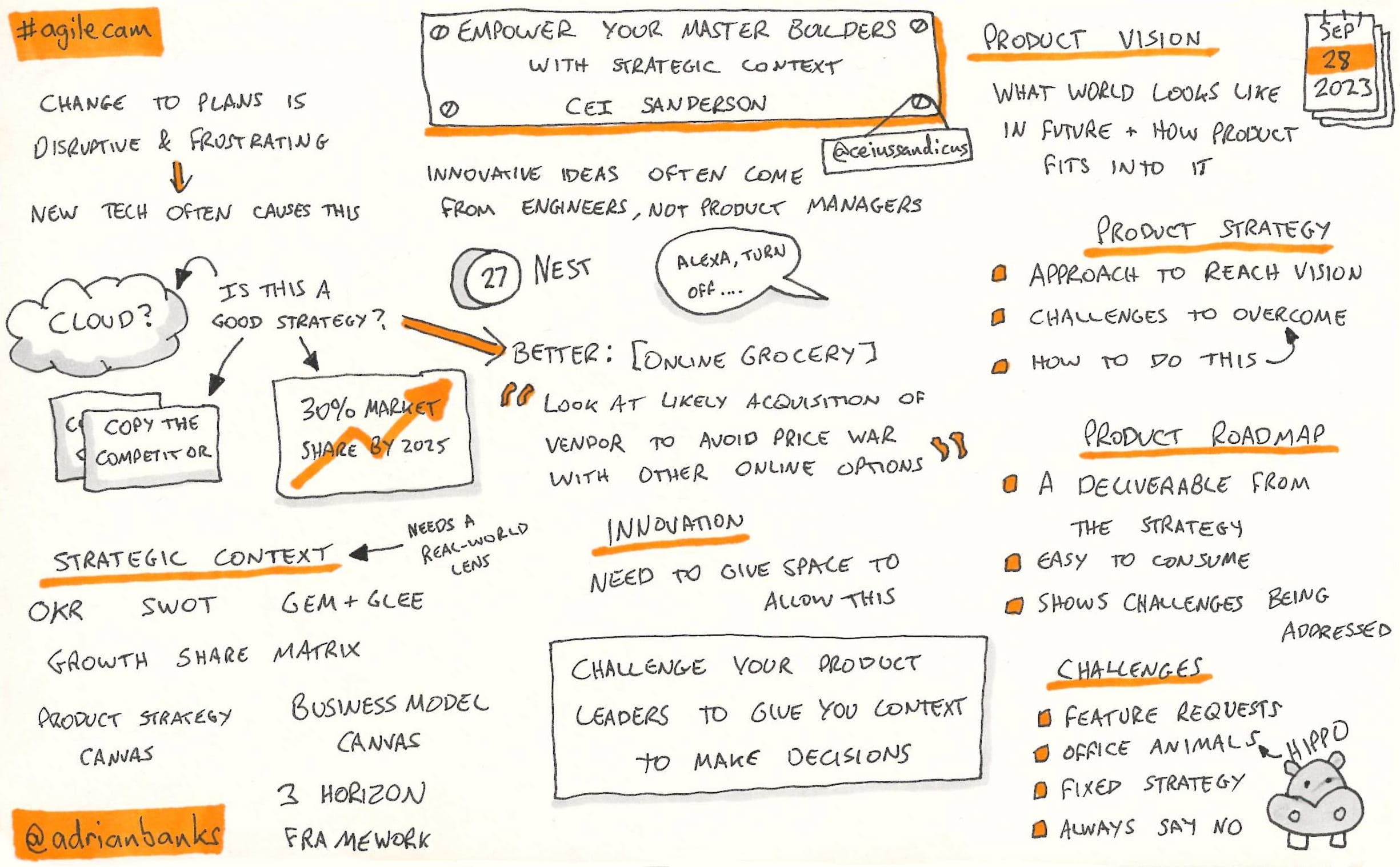
How to deal with uncertainties & risk in complex environments
Agile song-writing workshop
by Farah Egby
Something about the title of this workshop drew my attention, and always willing to try something new and to step out of my comfort zone, I went along. In the 90 minute session, a group of about 12 wrote and performed an original song, inspired by our love/hate of agile. We did this by first decomposing the song into its constituent parts (a chorus and three verses). We collectively worked on the chorus, which would have an uplifting feel to highlight the positives of agile. We then split into three groups, where each group worked on a different verse. After several minutes, we rotated to iterate on the verse created by a different group. We did this again until each group had worked on all three verses.
It was now time to put the lyrics to a melody. Farah had come pre-prepared with a chord progression and some suggeted styles, so we didn’t have to start completely from scratch. After a few false starts, a melody started to emerge. It wasn’t long before we had our completed masterpiece.

It was an interesting idea for a session, and one which I enjoyed taking part in. The following day, some of our group performed the song on stage in the welcome session at the start of the day - I chose to offer moral support from the audience.

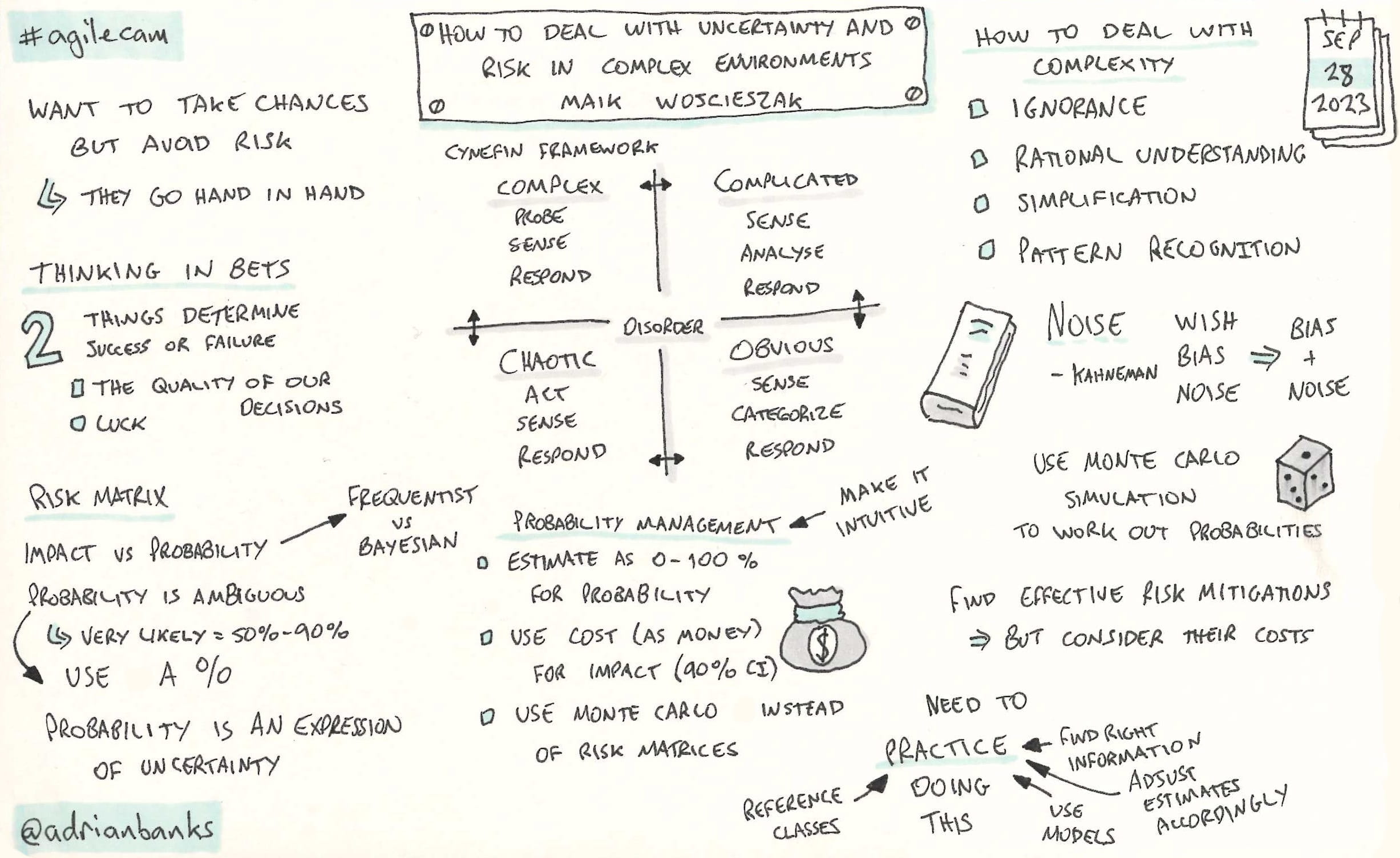
How to be agile with critical national priorities
by Anna Sherrington & Nick Smith
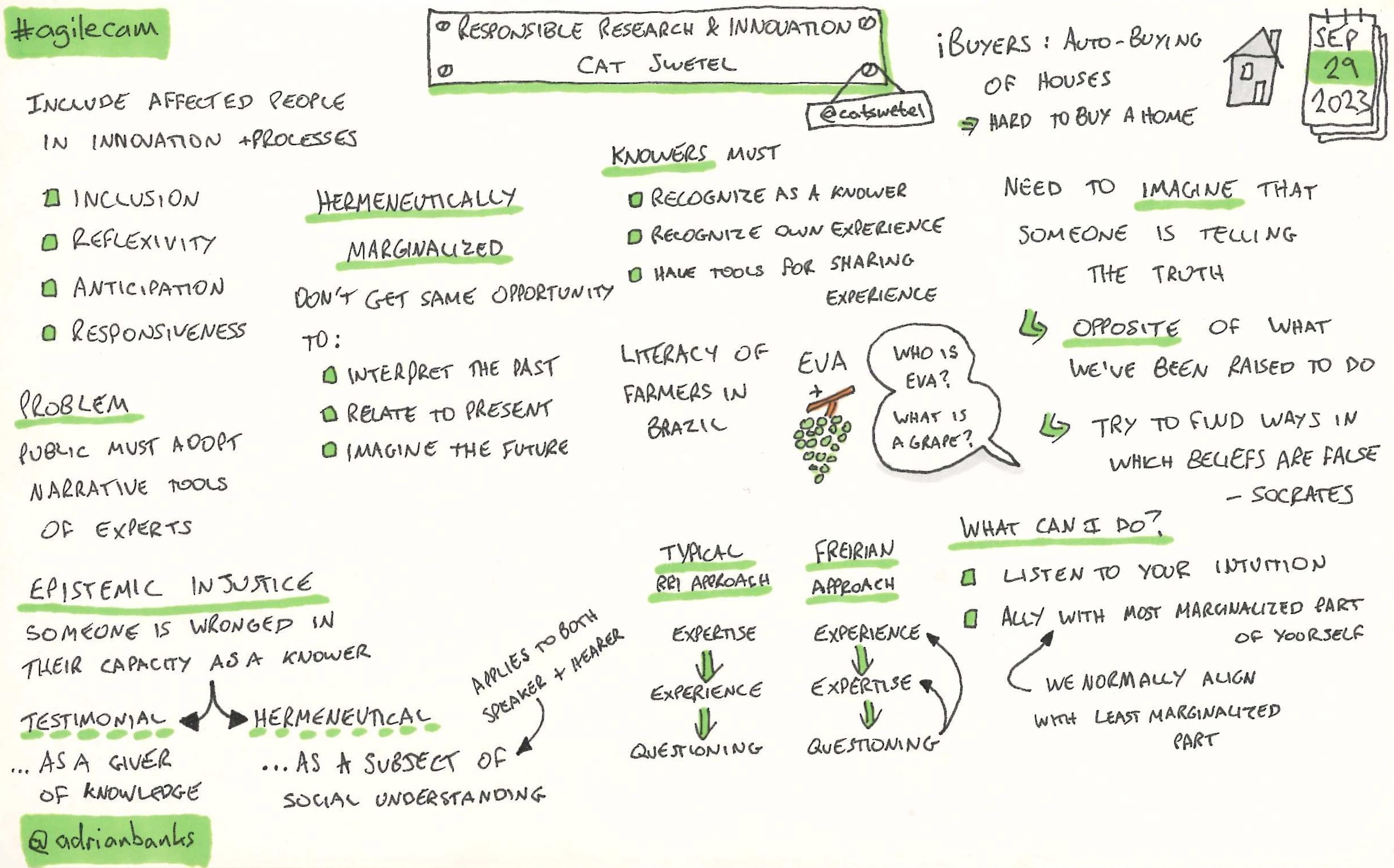
Responsible research and innovation
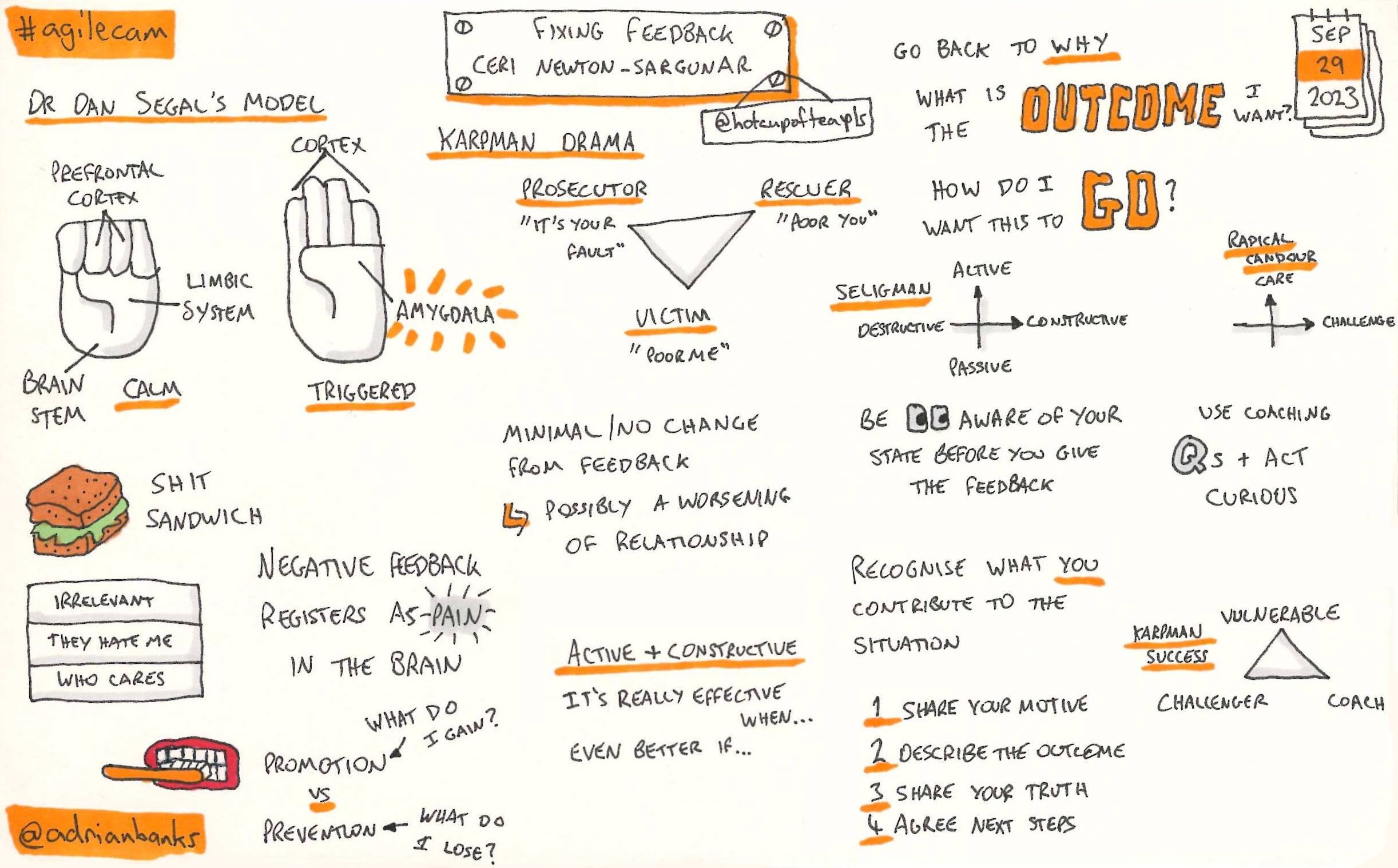
Fixing Feedback
Lean inceptions: how to set your teams up for success

Unleashing the transformational power of play. With Lego. Seriously
For my last session of the conference I chose to attend Robb’s session. I mainly chose this because it involved Lego, something which I have had a strong interest in since I was a child. Robb showed how using a small set of just 50 Lego pieces, insights can be discovered to aid with the coaching process. It was also fun to build some simple models as the workshop progressed, including one challenge of “build a tower with you in it”. We also got to keep the Lego at the end of the session :)

StaffPlus London 2023
I spent a few days this week at the first ever StaffPlus London, a conference for senior individual contributors being run alongside the LeadDev London event. The conference was compèred by Tanya Reilly, author of The Staff Engineer’s Path.
Unlinke other conferences I’ve been to, there was only one track which made choosing what sessions to see quite easy. The talks were of varying lengths, and there were a lot of them, which made sketchnoting them quite a task.
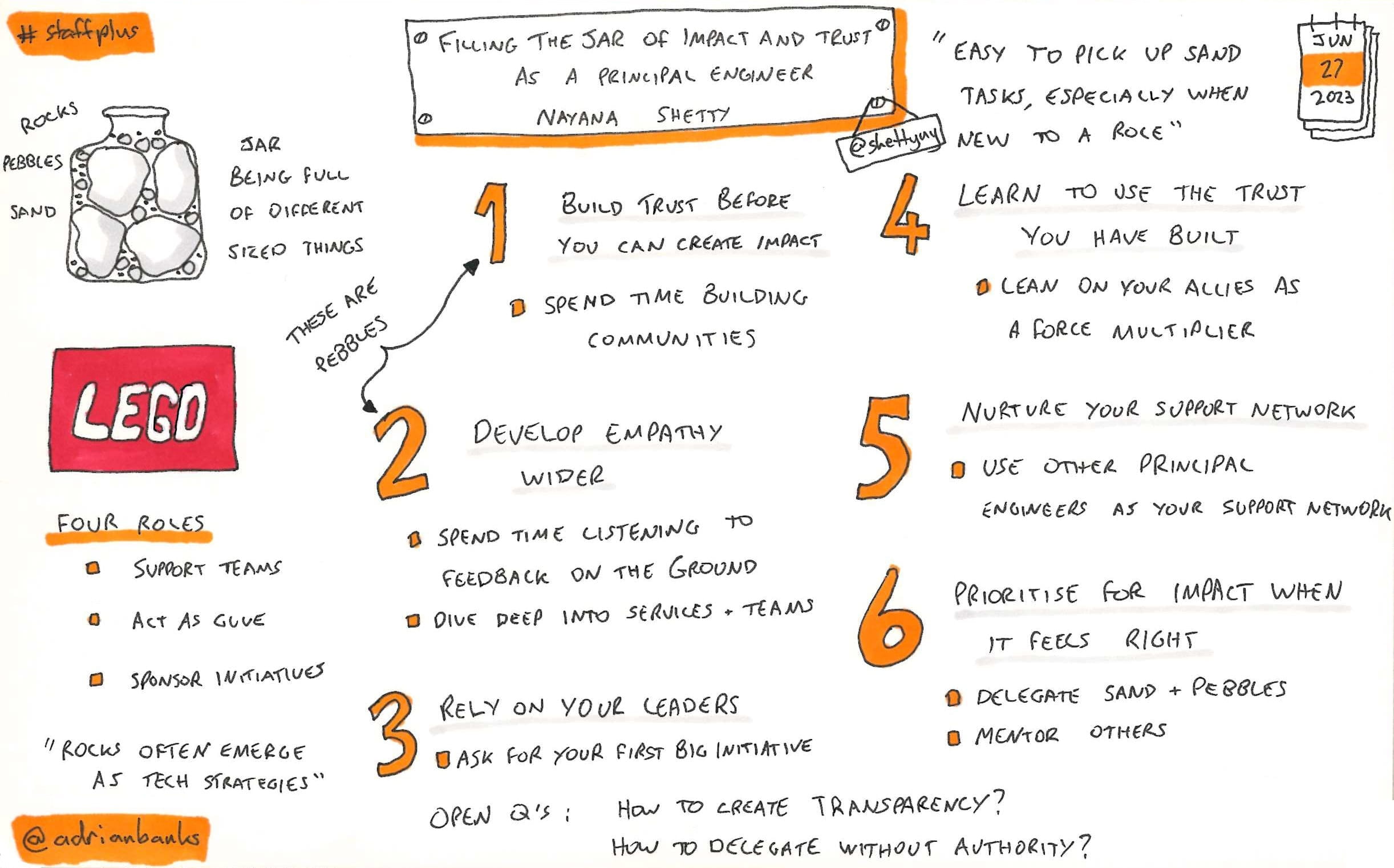
Filling The Jar Of Impact And Trust As A Principal Engineer
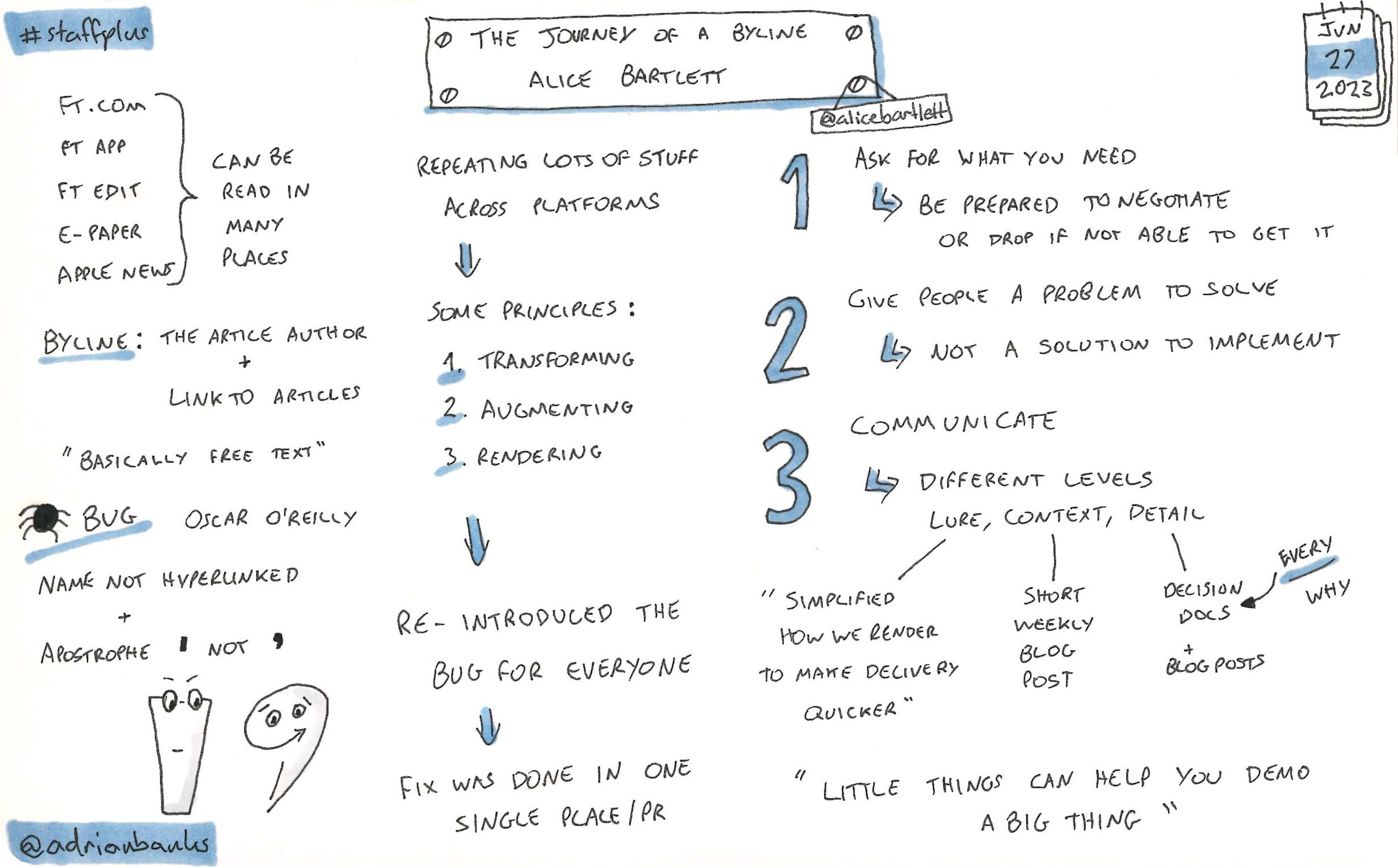
The Journey Of A Byline
Running Large Scale Migrations Continuously
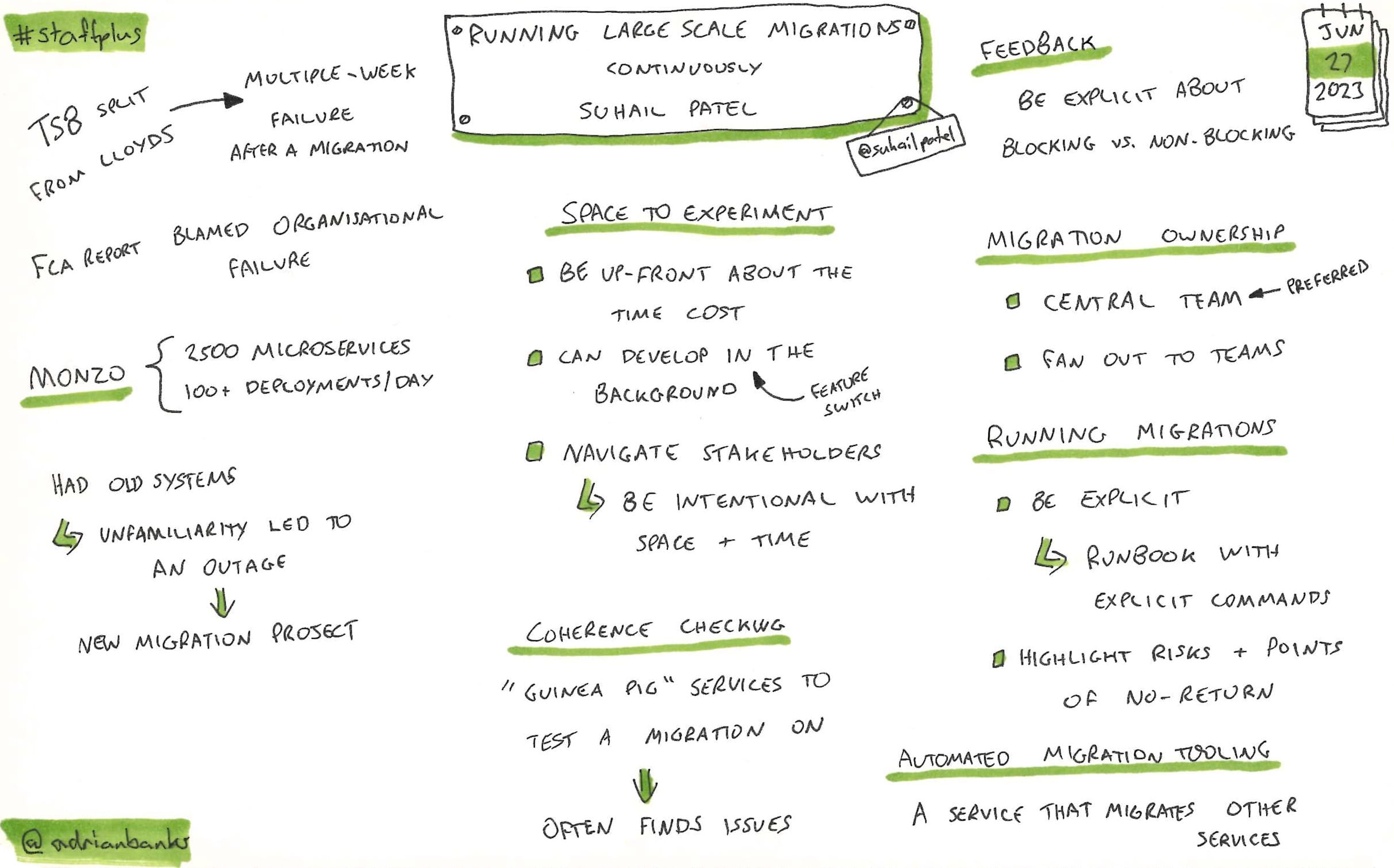
How To Not Lose Friends And Alienate Yourself

Scaling Your Influence Through Documentation

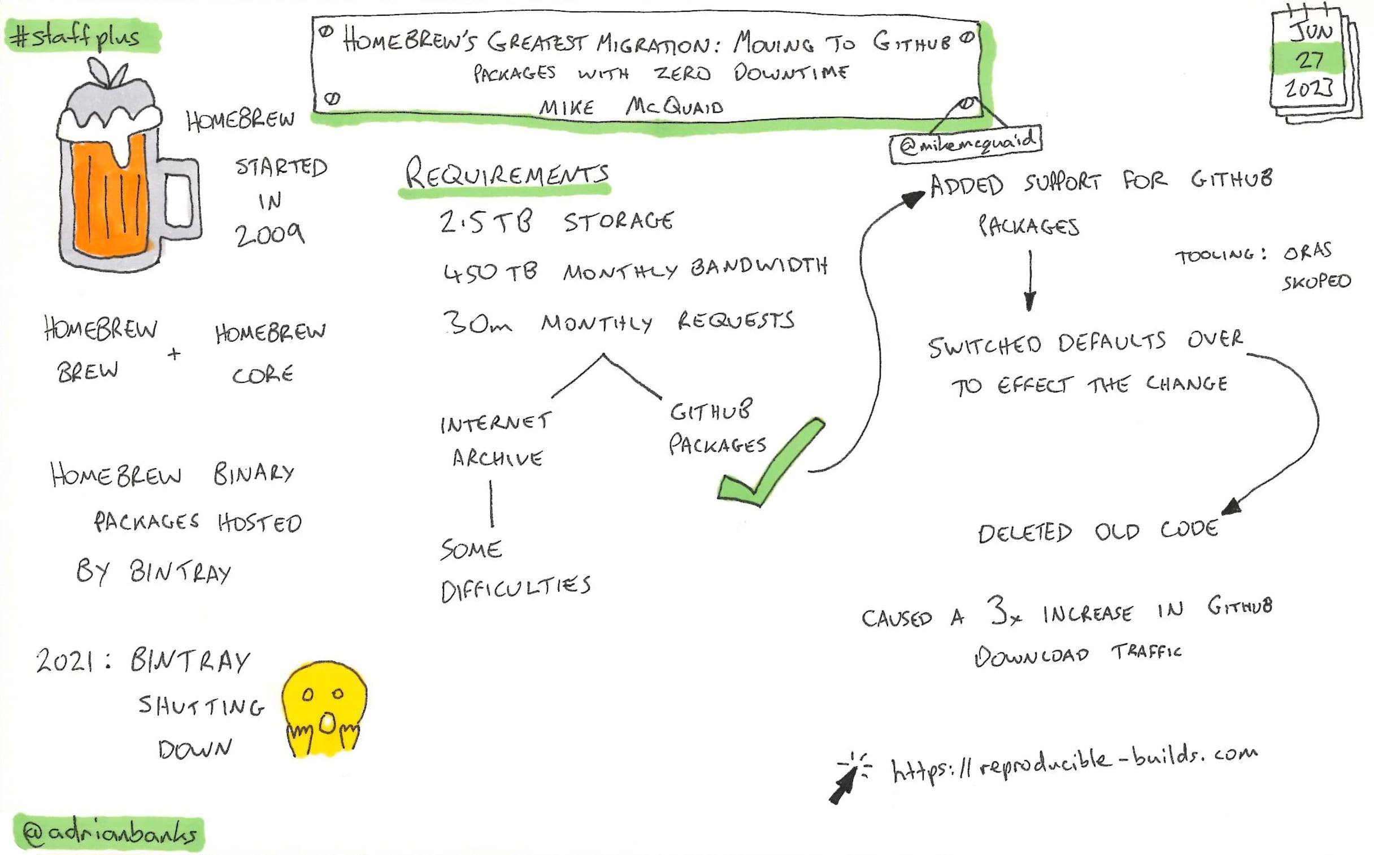
Solving The Puzzle Of Staff+ Time Management
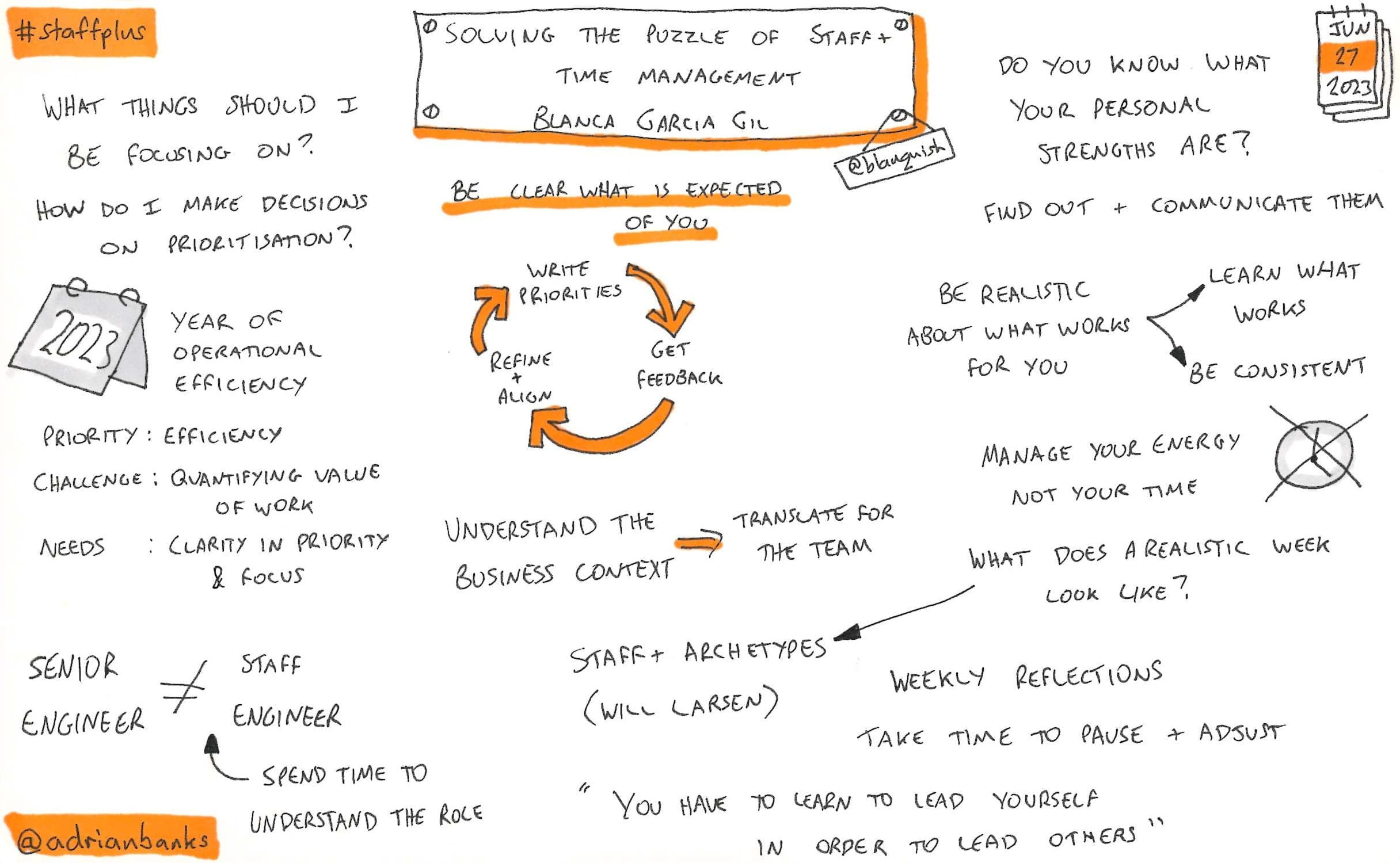
Maximising Your Impact When Context Switching
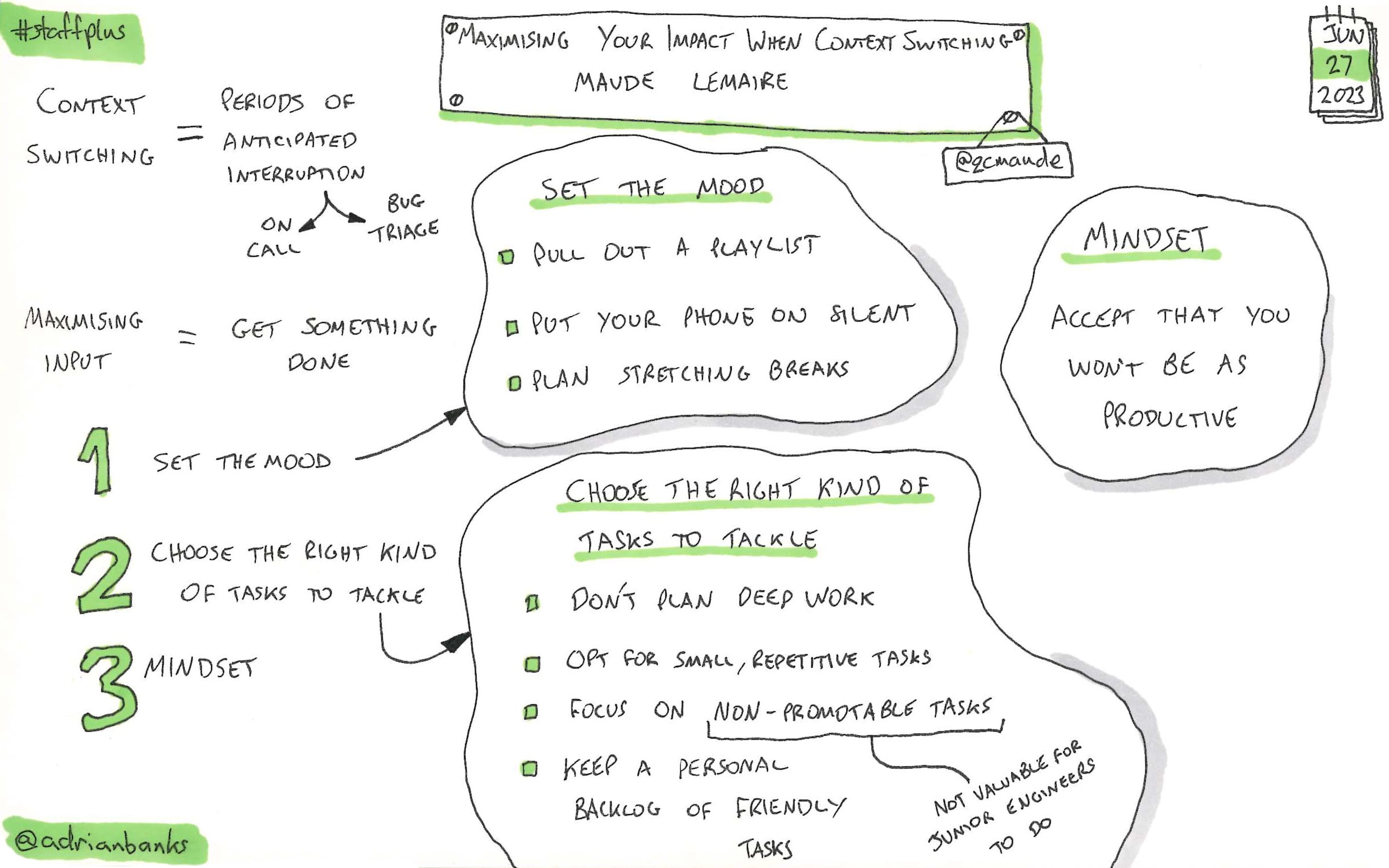
Homebrew’s Greatest Migration: Moving To Github Packages With Zero Downtime
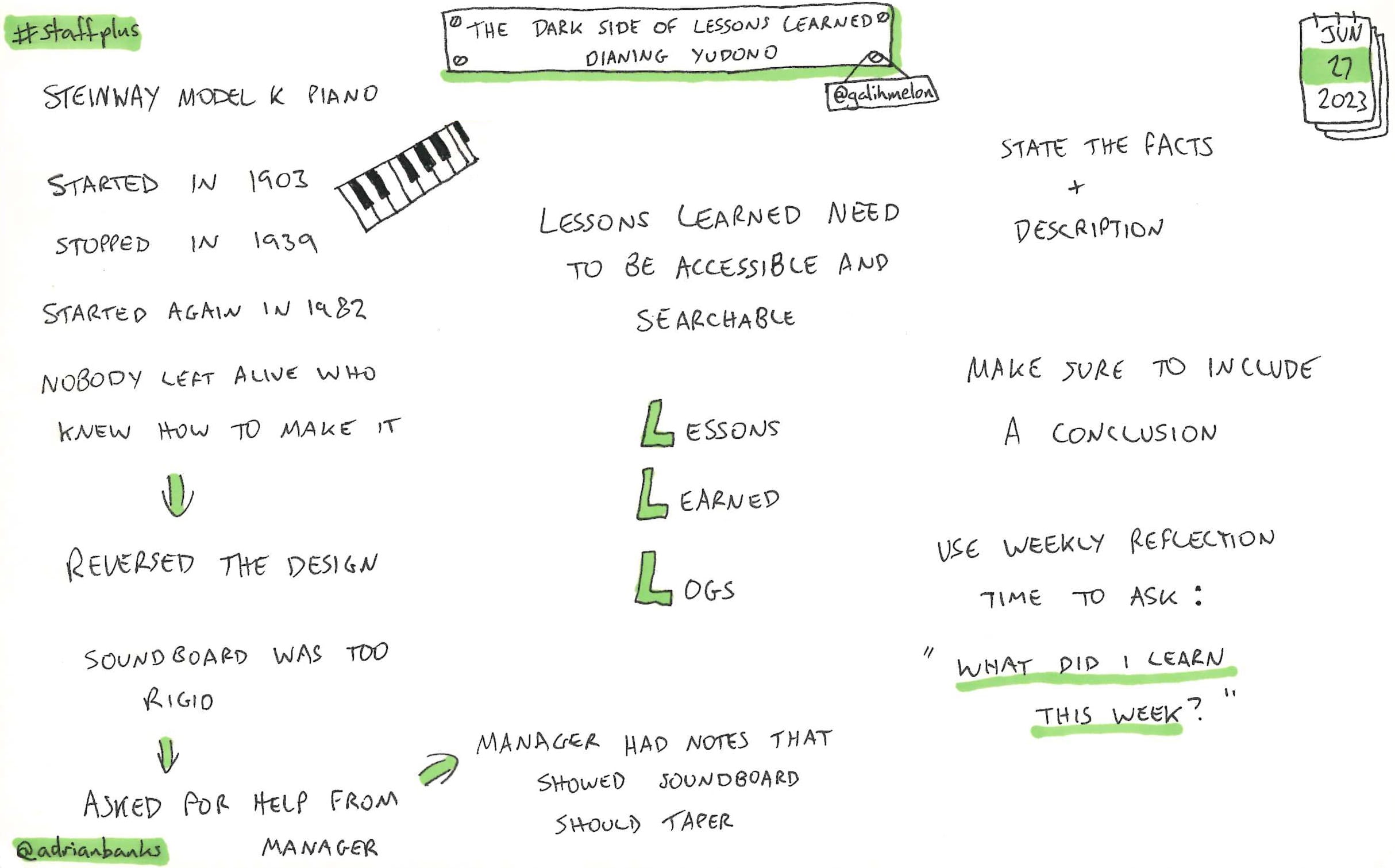
The Dark Side Of Lessons Learned
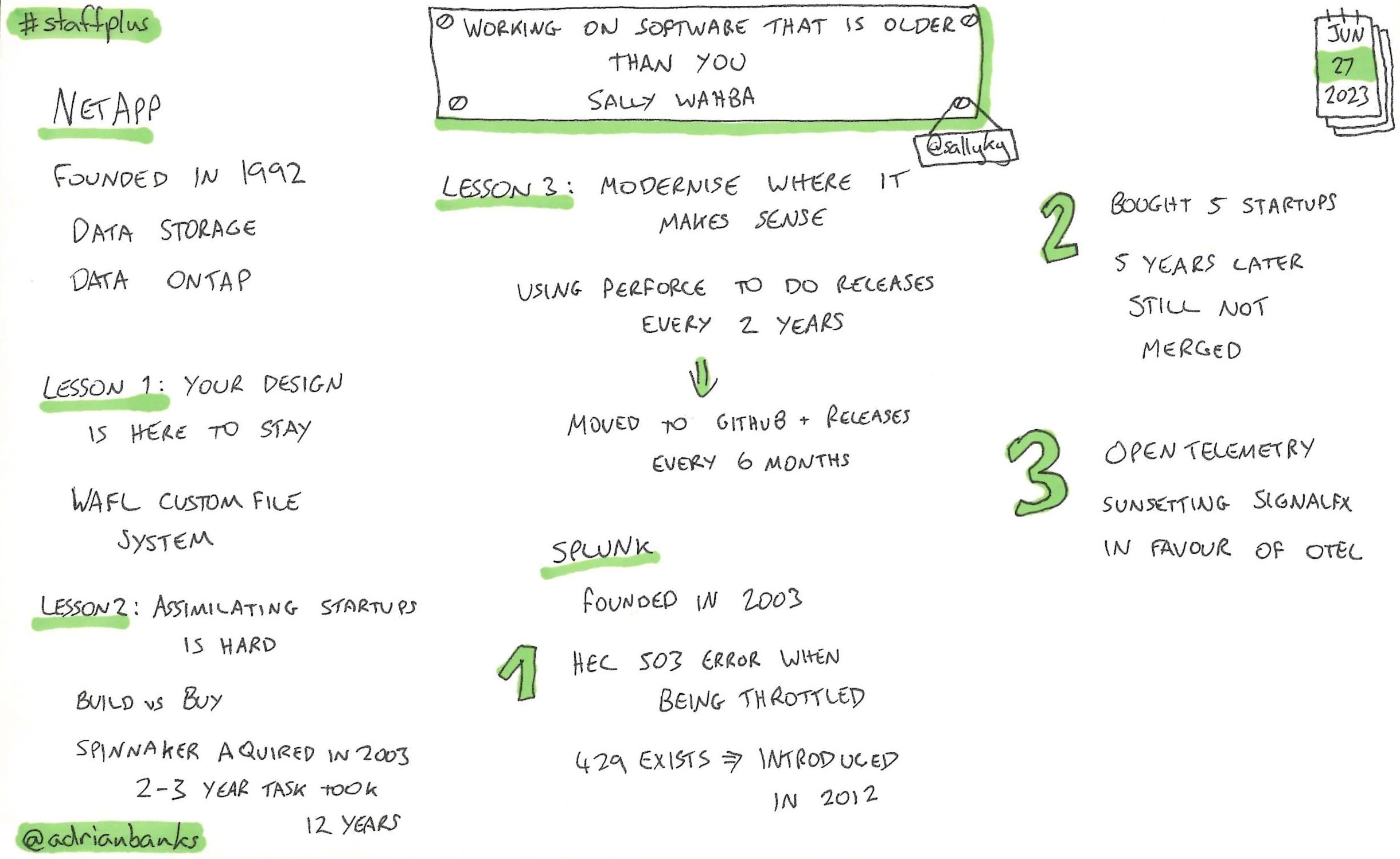
Working On Software That Is Older Than You
Practical Systems Thinking For Software Engineers

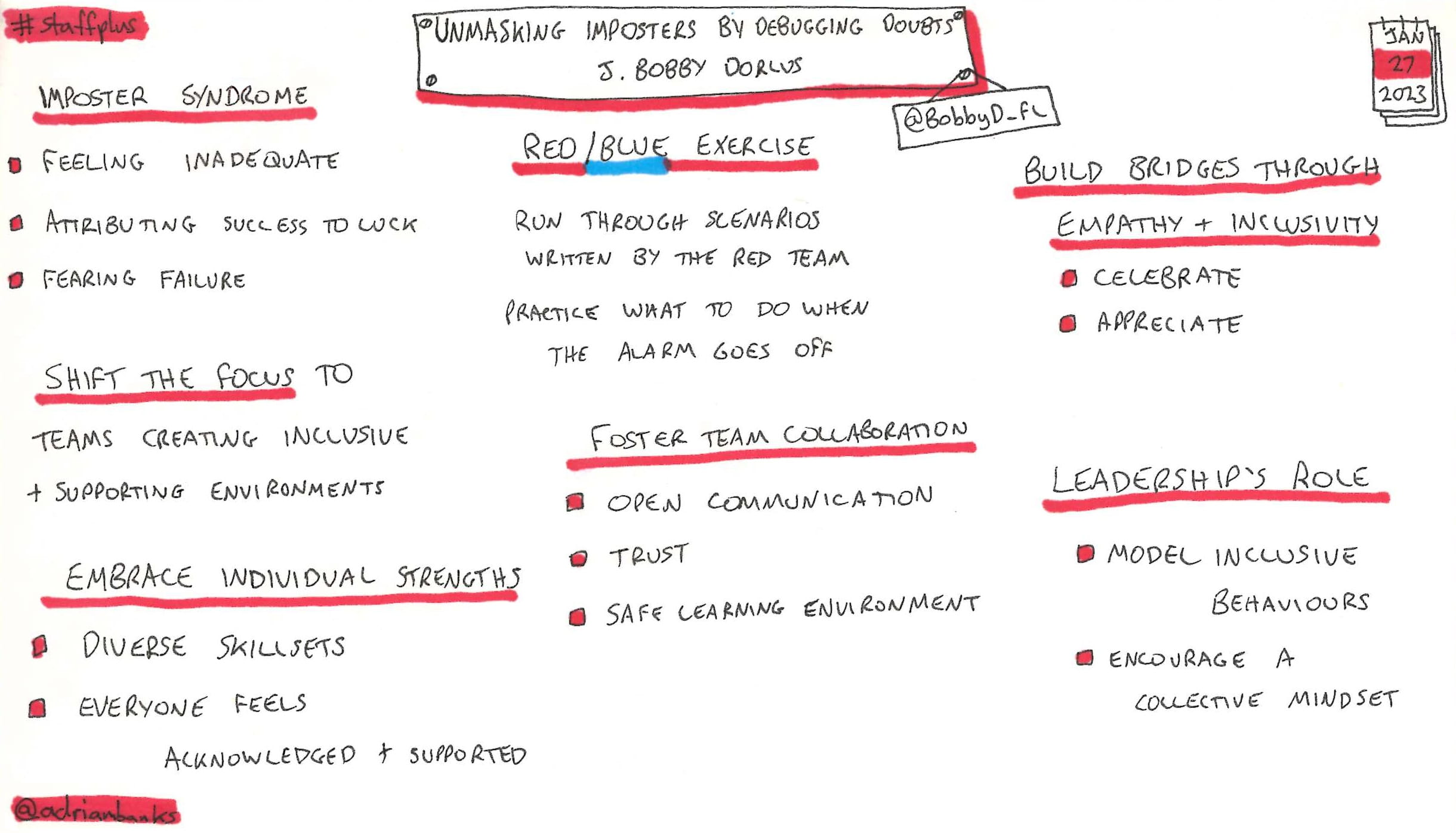
Unmasking Imposters By Debugging Doubts
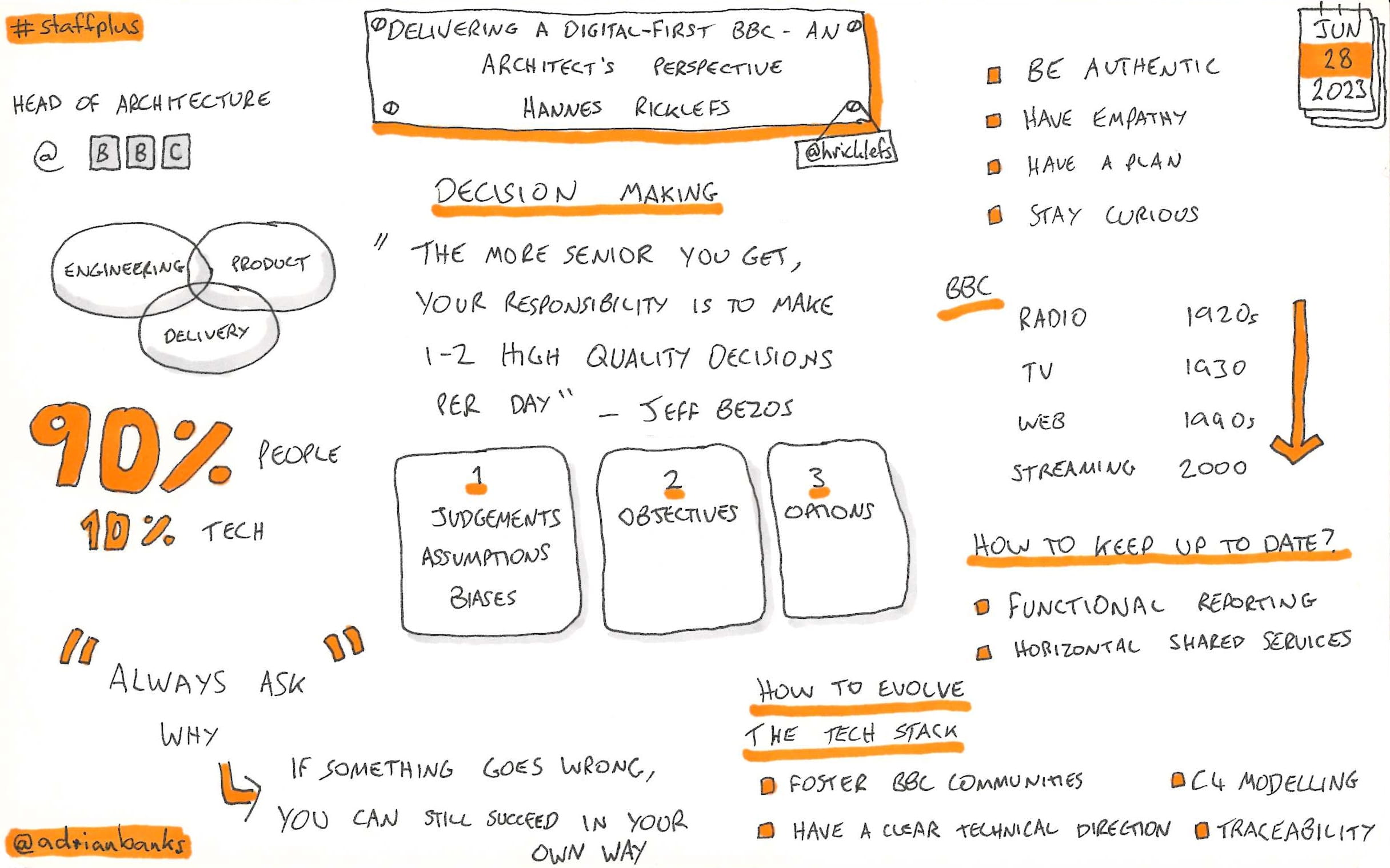
Delivering A Digital-First BBC - An Architect’s Perspective
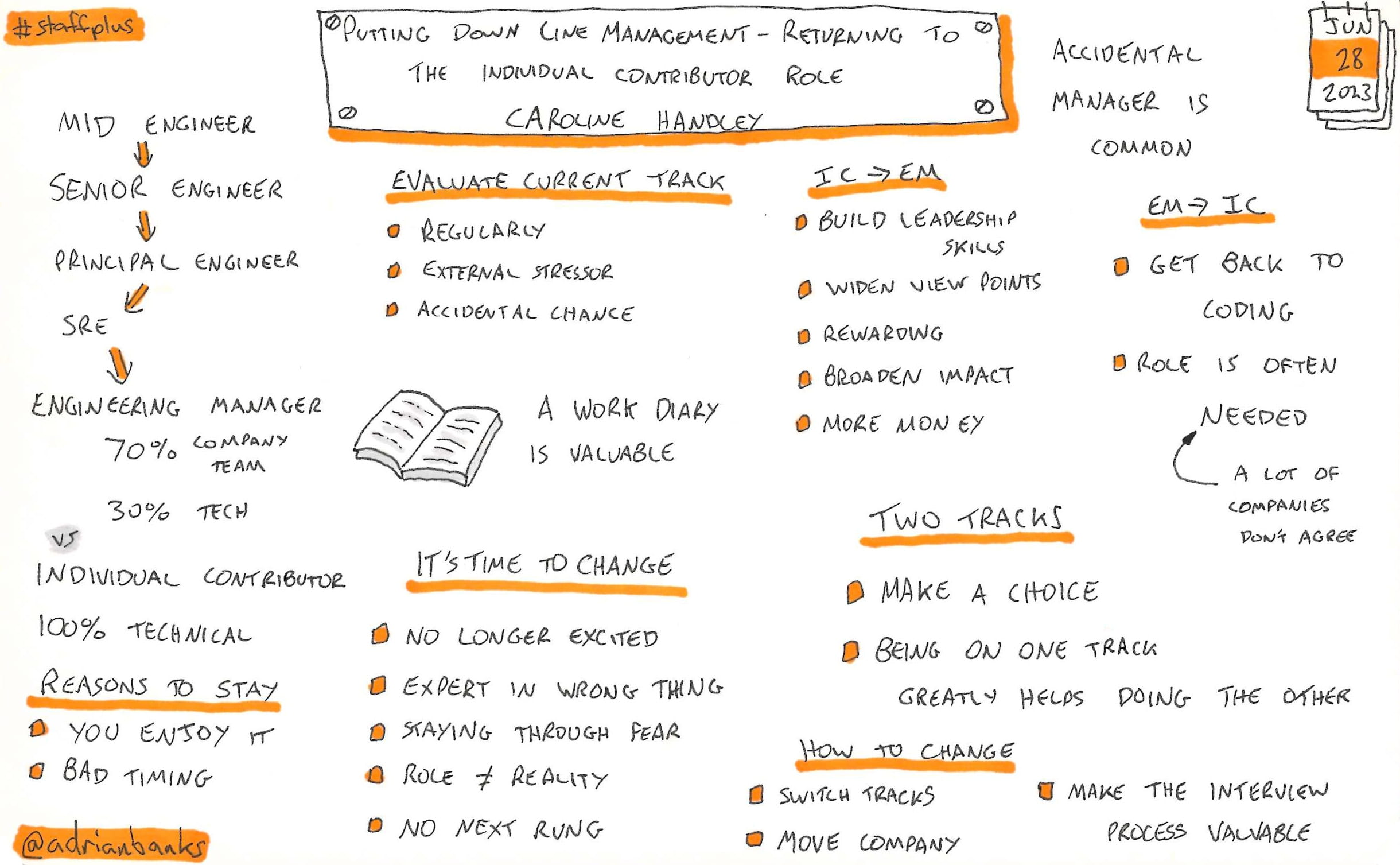
Defining A Technical Visiion
by Eamon Scullion
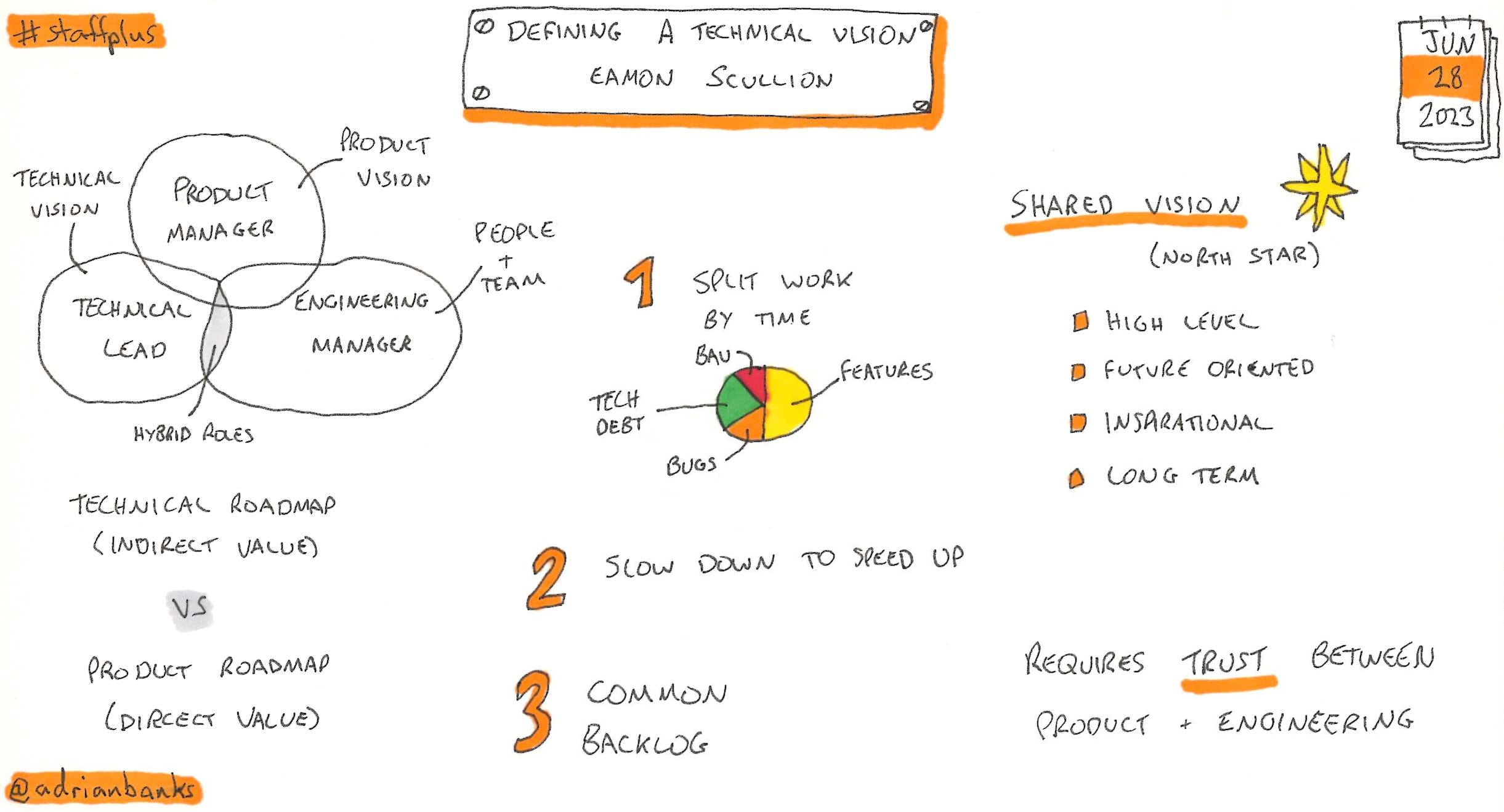
Putting Down Line Management - Returning To The Individual Contributor Role
by Caroline Handley
Cloud Infrastructure Architecuture For Nubank’s Global Expansion
by Lais Oliviera

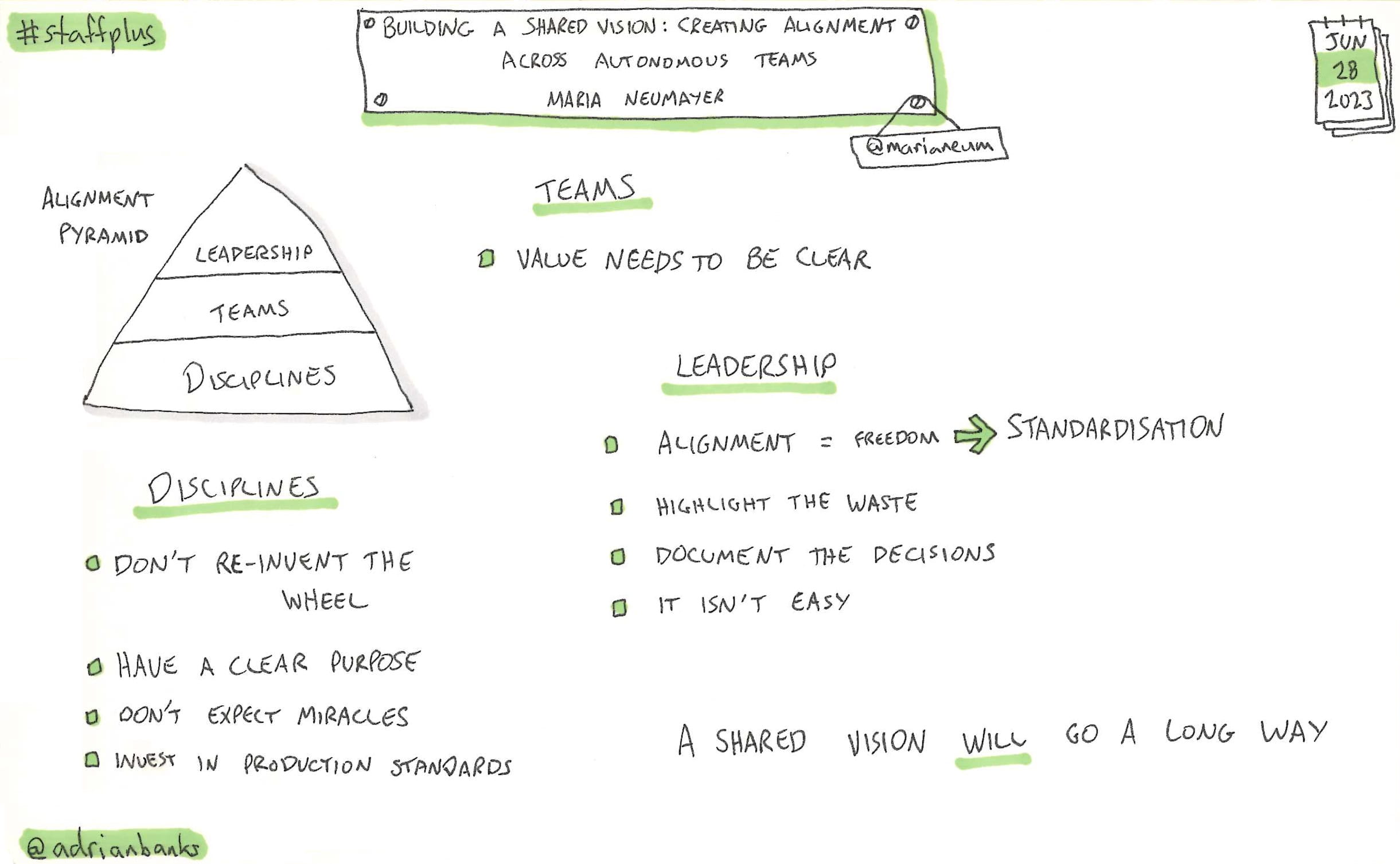
Building A Shared Vision: Creating Alignment Across Autonomous Teams
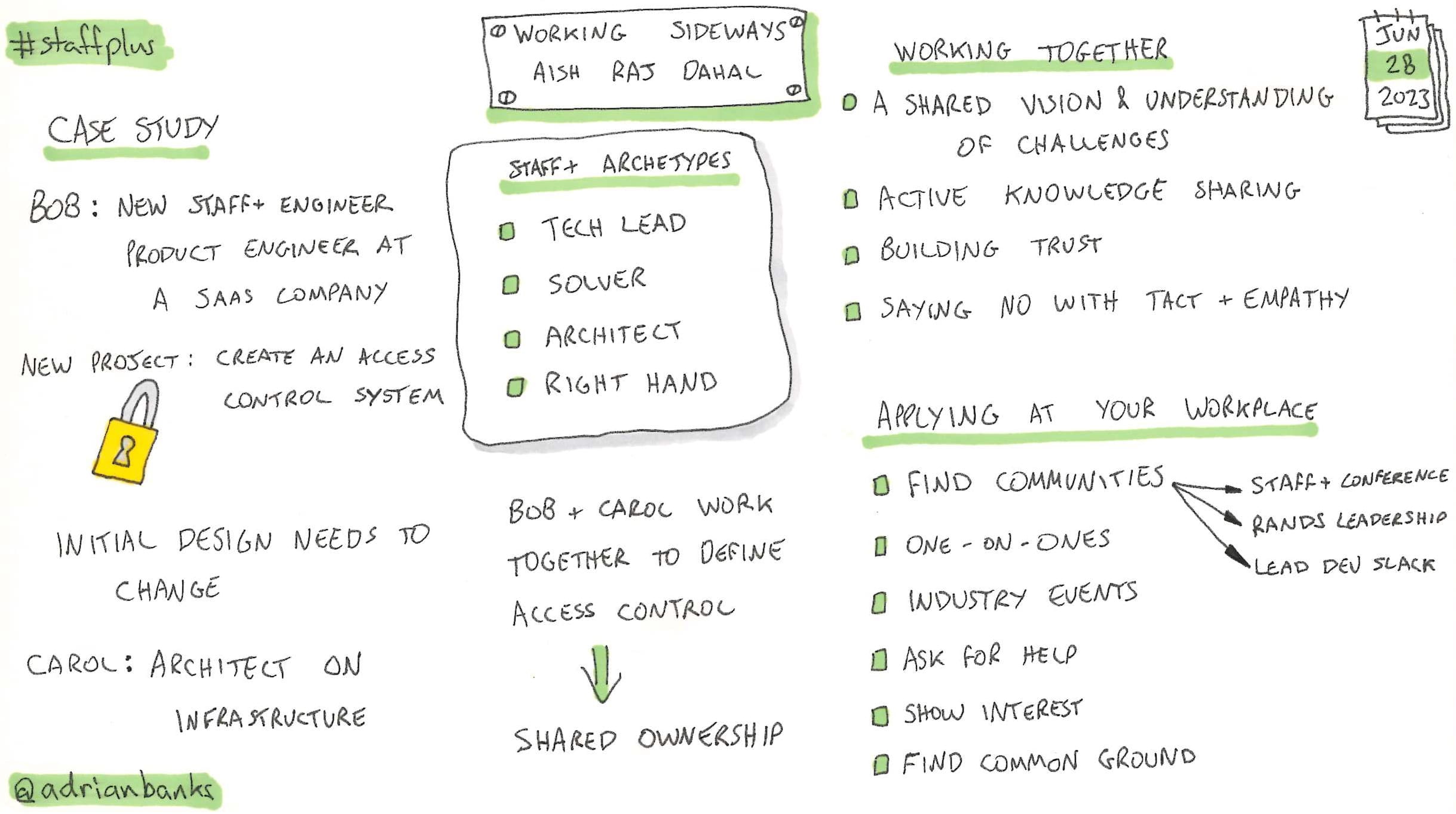
Working Sideways
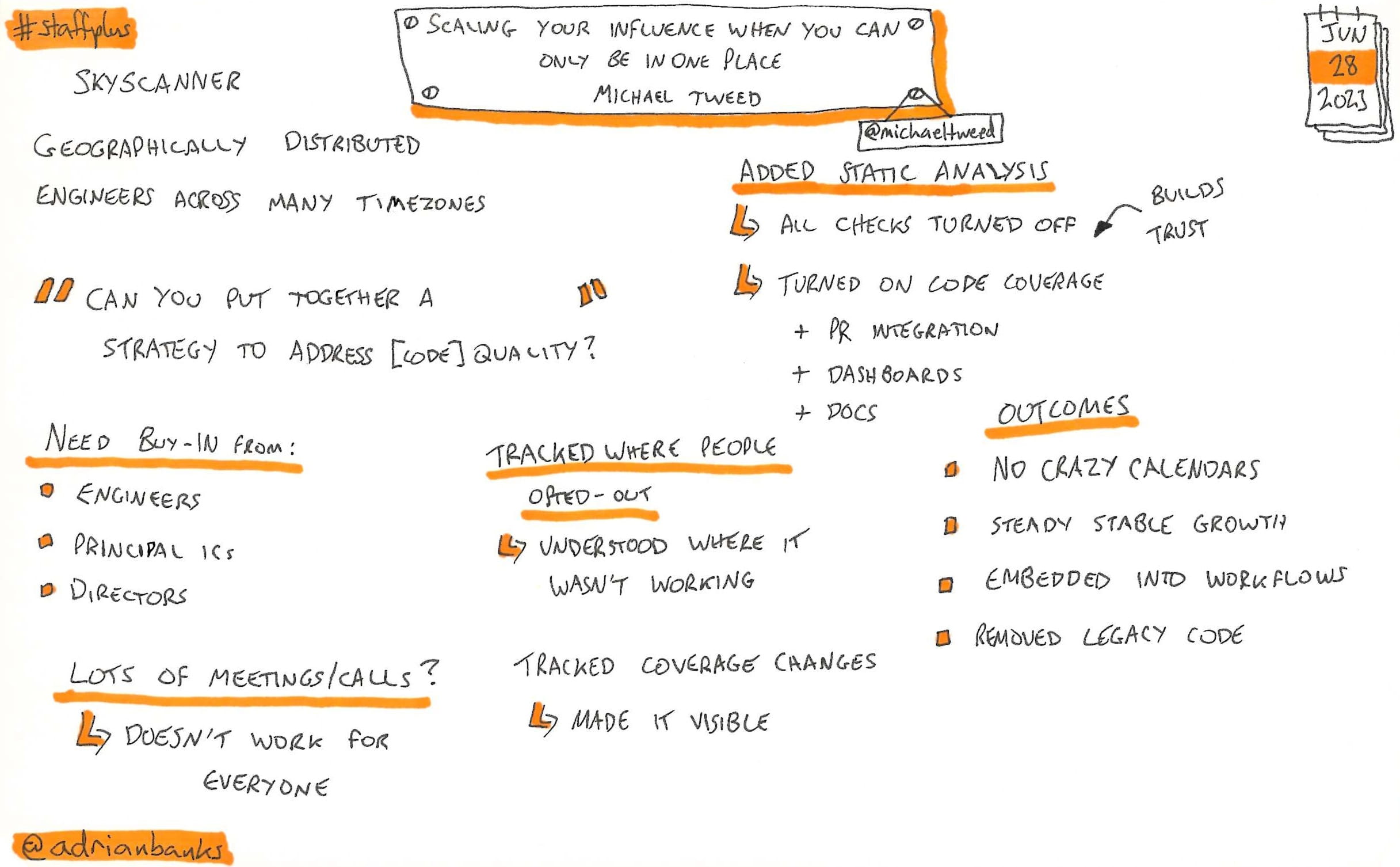
Scaling Your Influence When You Can Only Be In One Place
The Dark Side Of Standardisation

Librarian’s Guide To Documentation
by Kaitlyn Tierney

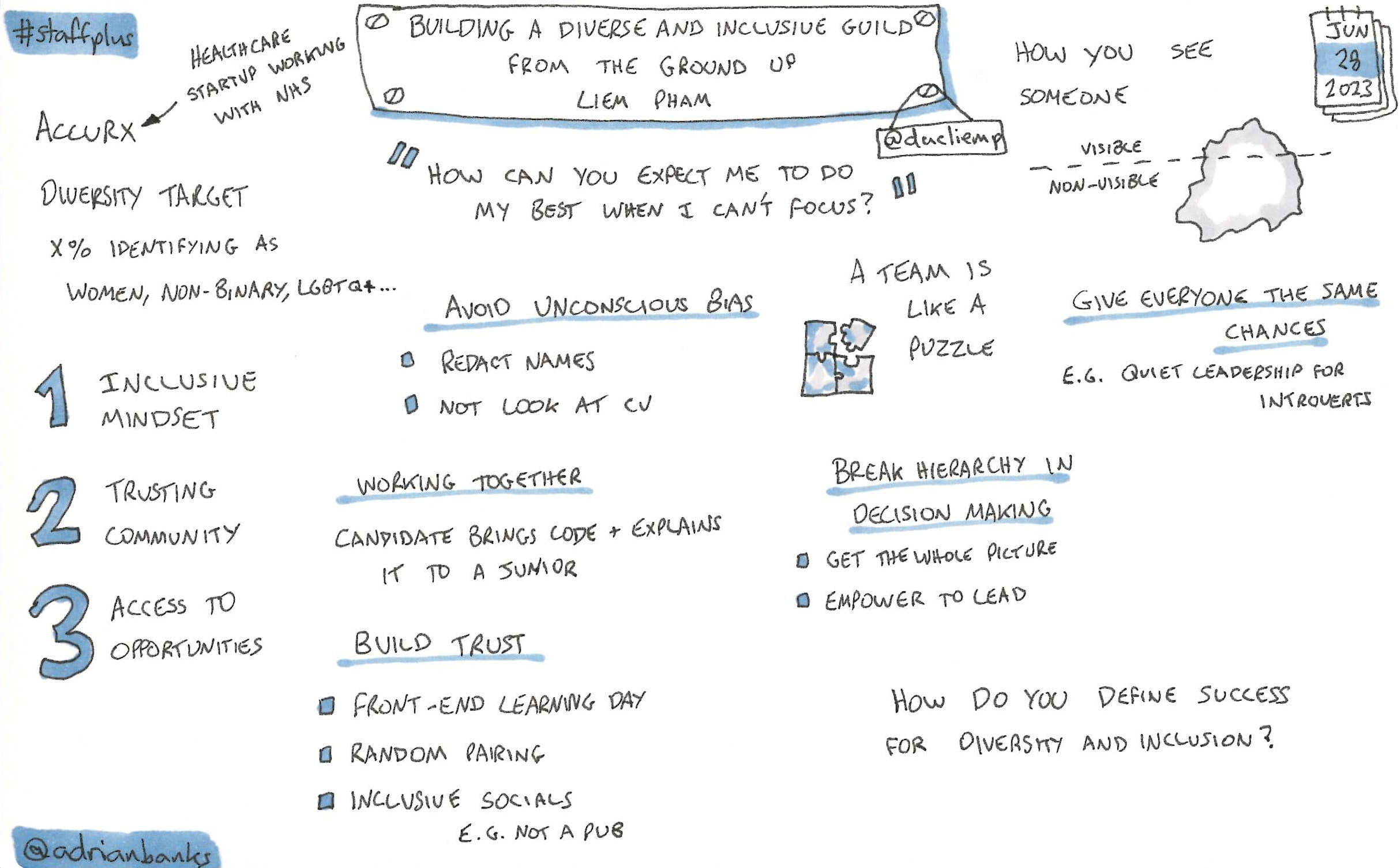
Building A Diverse And Inclusive Guild From The Ground Up
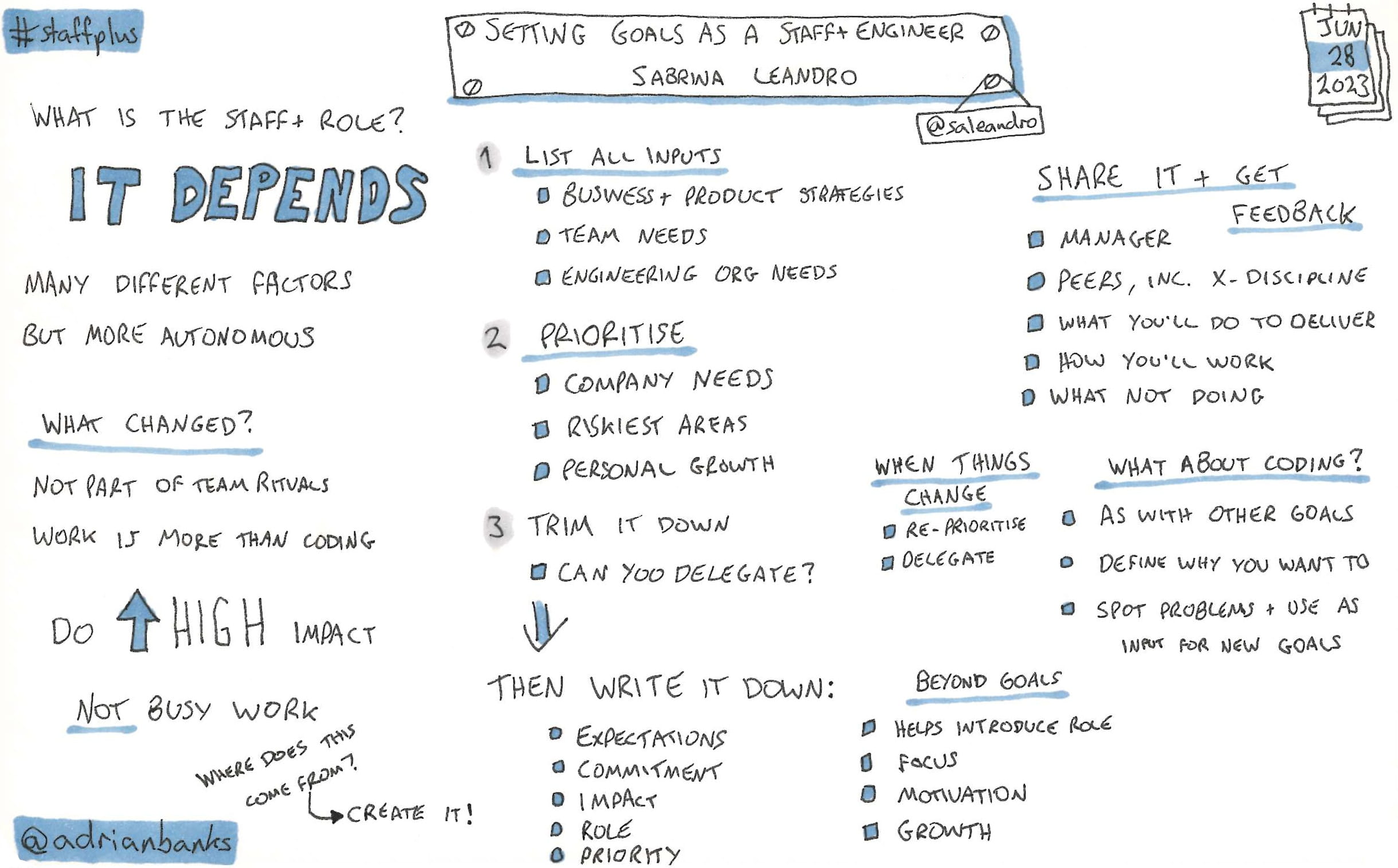
Setting Goals As A Staff+ Engineer
DDD South West 11
A few weeks ago I attended DDD South West. It was run very similar to last year’s event, but was much better attended. Here are my sketchnotes of the talks.
Being Staff Plus

User Testing In Production

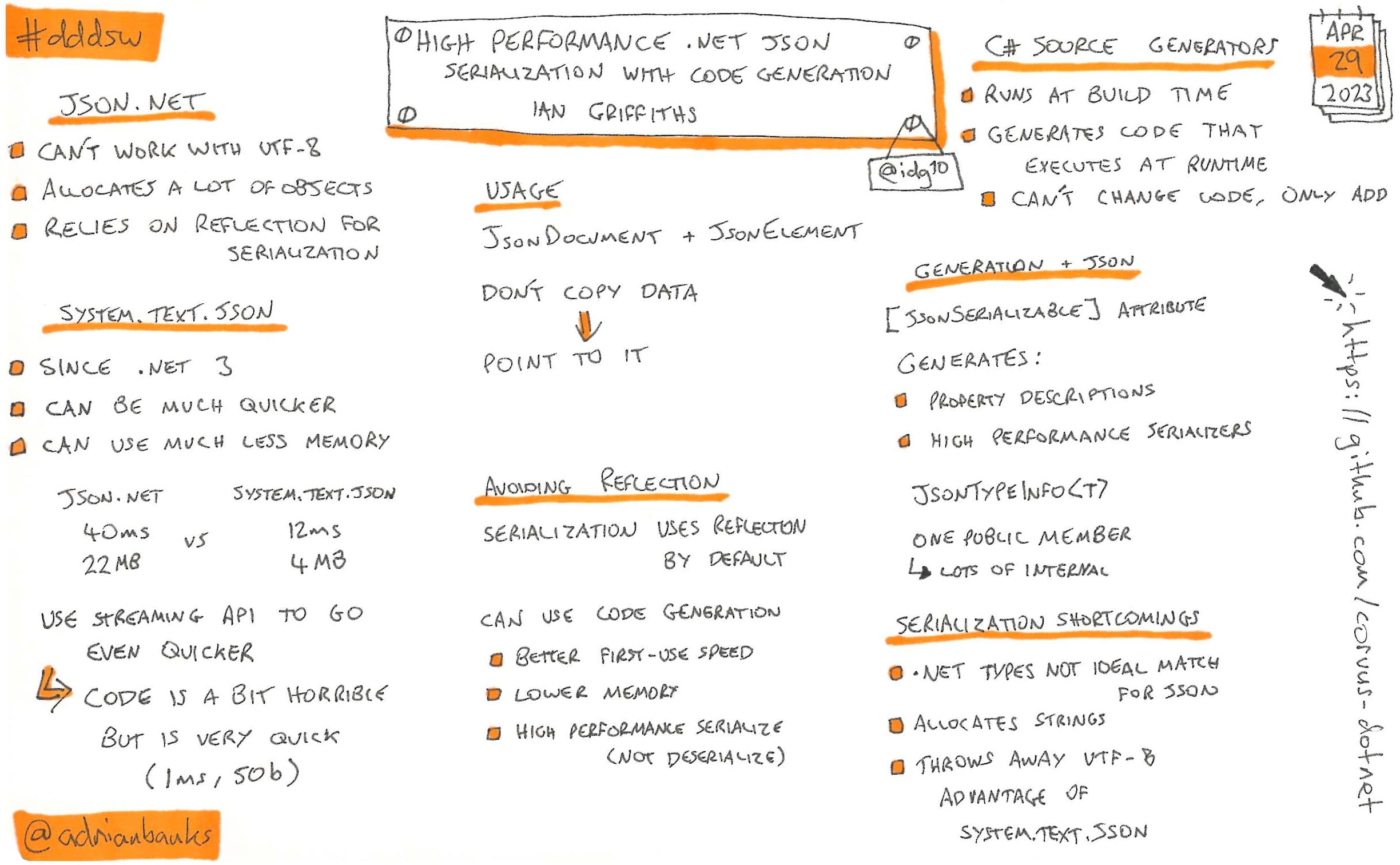
High Performance .Net JSON Serialization With Code Generation
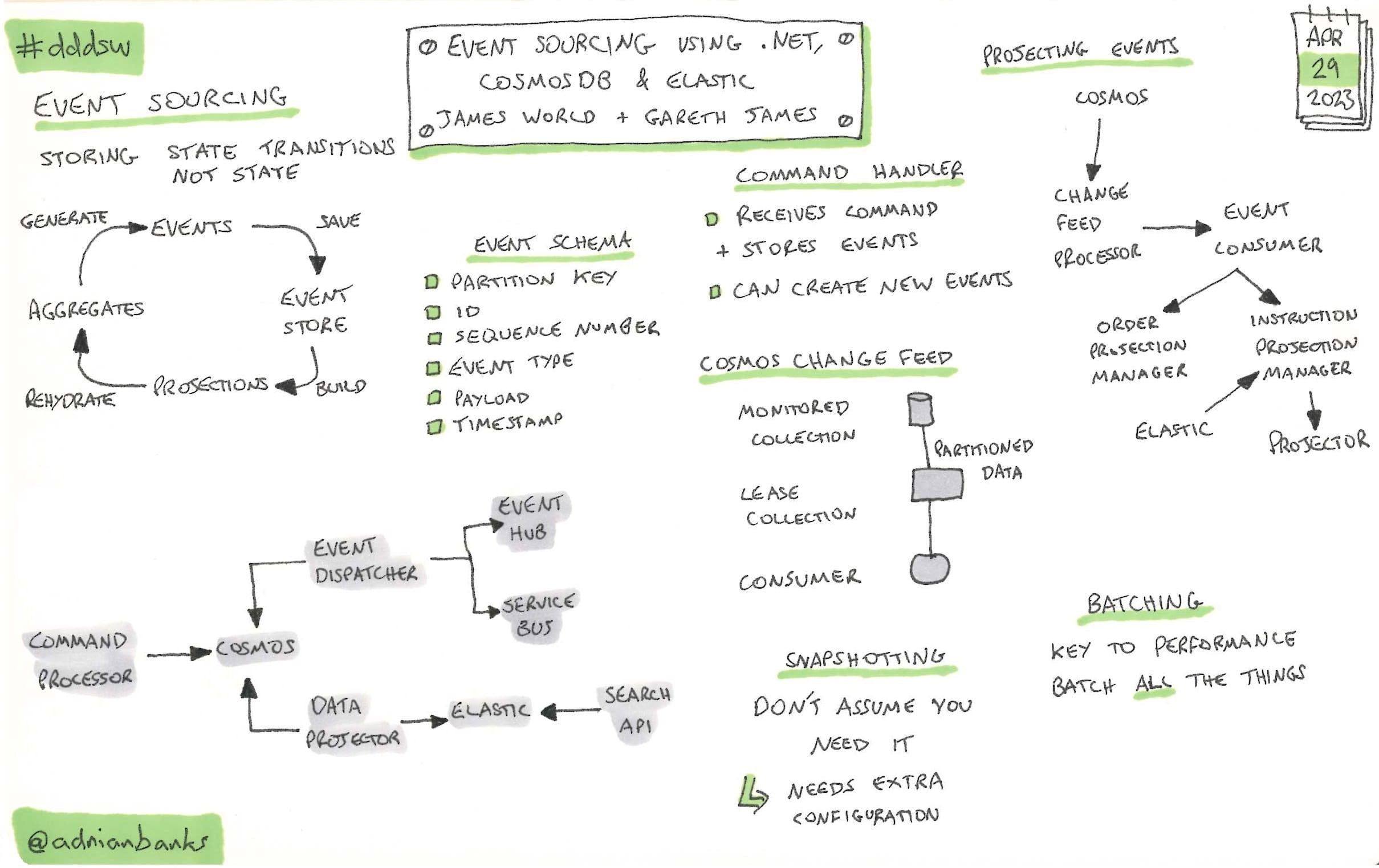
Event Sourcing Using .Net, CosmosDB And Elastic
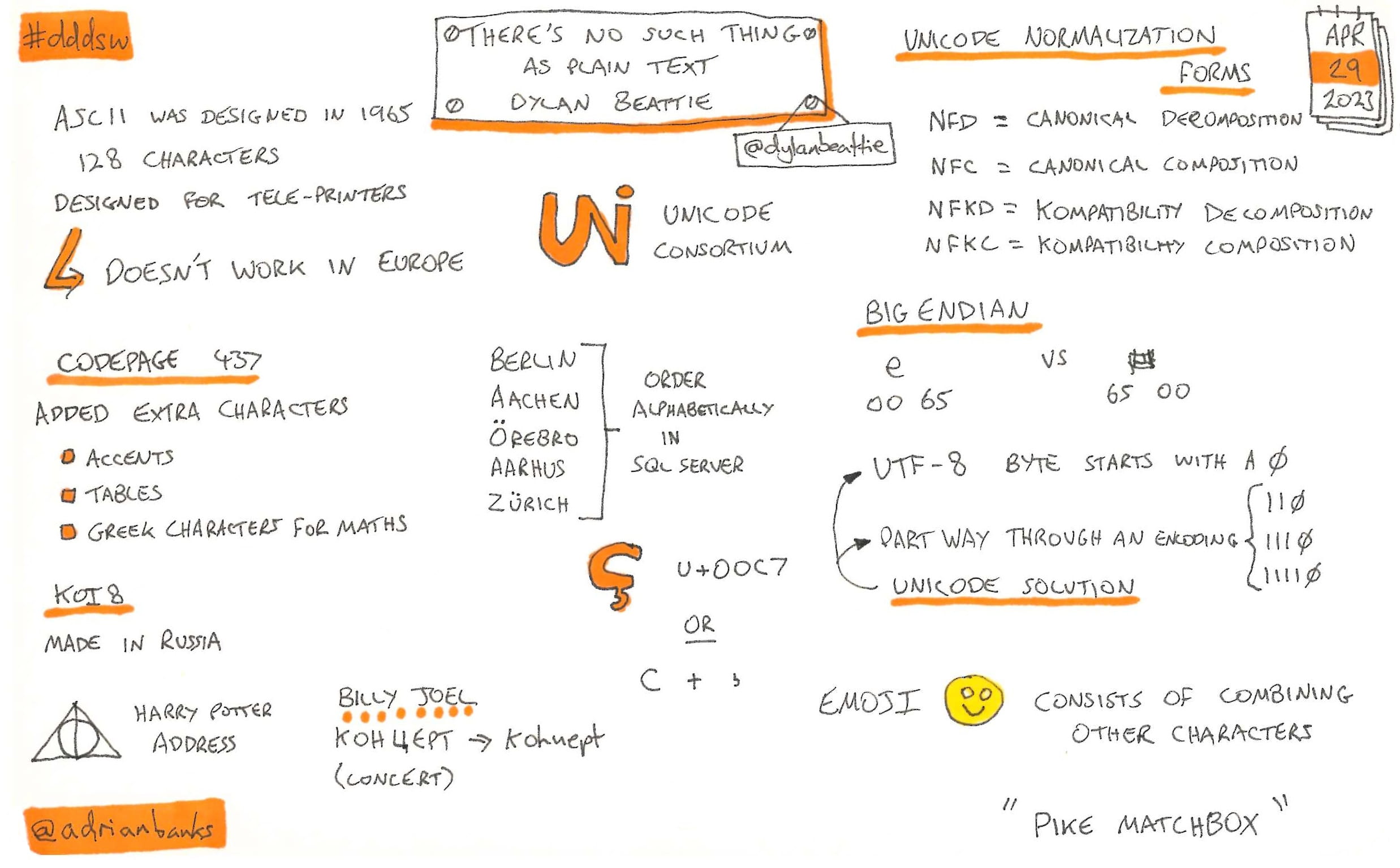
There’s No Such Thing As Plain Text
DDD South West 10
DDD South West returned for its 10th event a few weeks ago. With it came a few new organisers, plus a brand new venue which was great. I took the opportunity to have a long weekend in Bristol, a city that I always enjoy visiting.
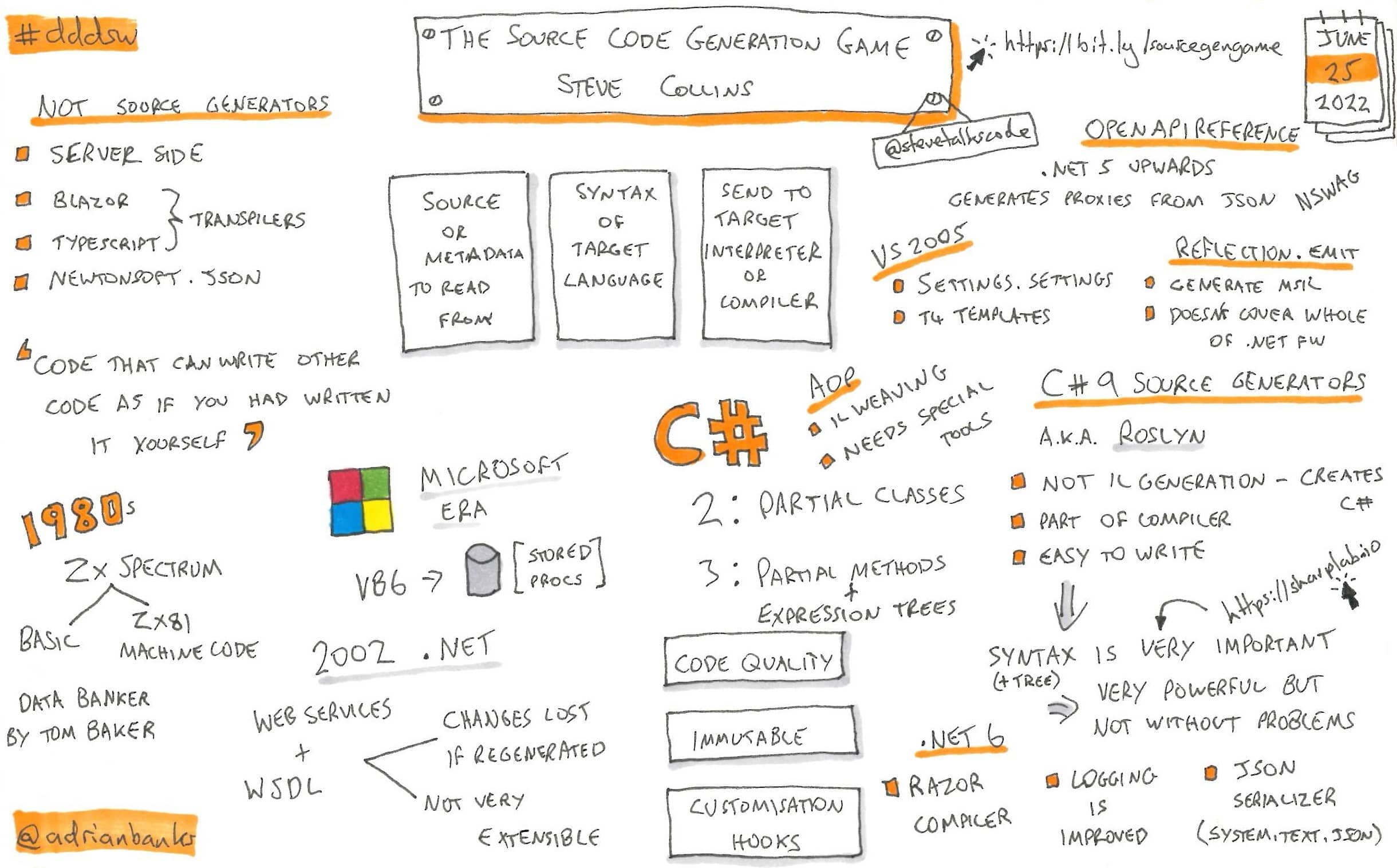
The Source Code Generation Game
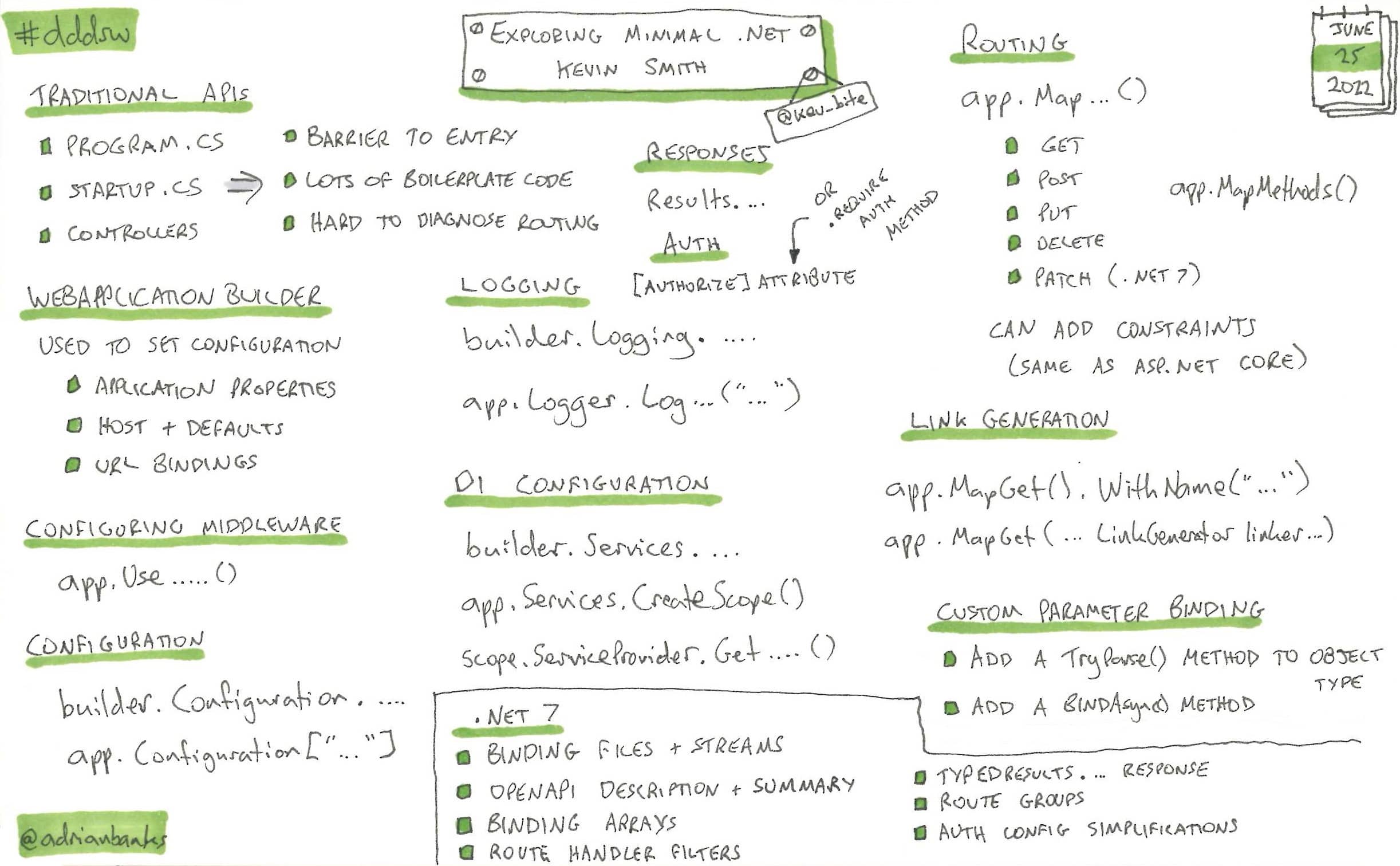
Exploring Minimal .Net
Data Scientists: Making Shit Up Since 1974

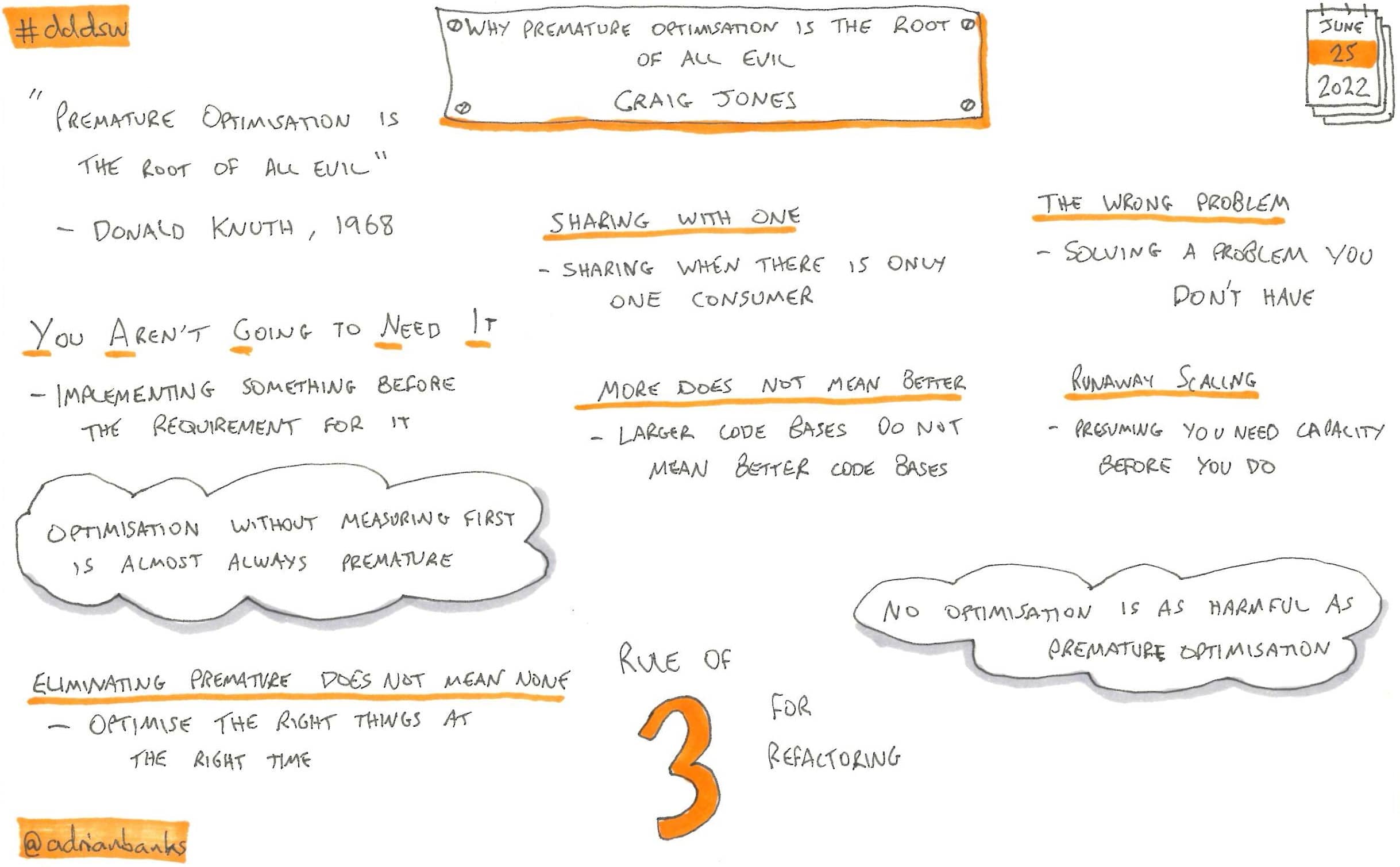
Why Premature Optimisation Is The Root Of All Evil
by Craig Jones
Let’s Stop Blaming Our Users For Getting Hacked When It Is Our Problem To Solve

NDC London 2022
After a hiatus of over two years due to the pandemic, NDC London returned this week to an in-person conference. After attending many virtual user groups, conferences, and training courses, it was great to meet up again with friends I’ve got to know through attending conferences over the years (and also a few former work colleagues as an unexpected bonus). The conference itself didn’t feel any different from the previous NDC London events I’ve attended, with a great venue, lots of interesting talks, and some excellent hospitality laid on by the organisers.
Here are the sketchnotes that I made for the talks that I attended.
The Last Twenty Years Of Software Development
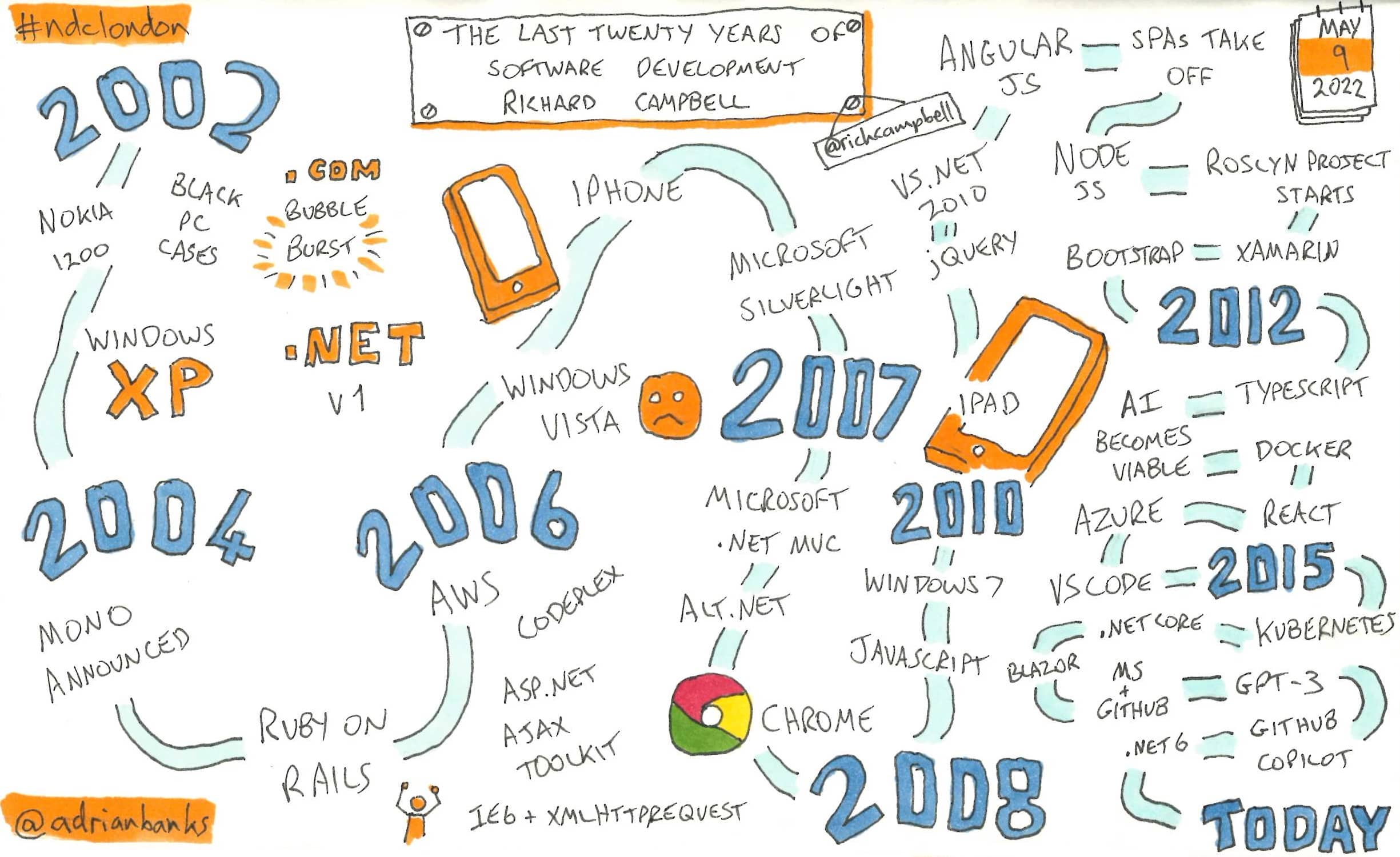
Richard went over the history of the past twenty years of software development, demonstrating how both technology and the big companies have changed in that time period. What was notable was the acceleratation in the pace of change in technology over the latter half of the timeframe.
The Curious Incident In Your Software In The Daytime
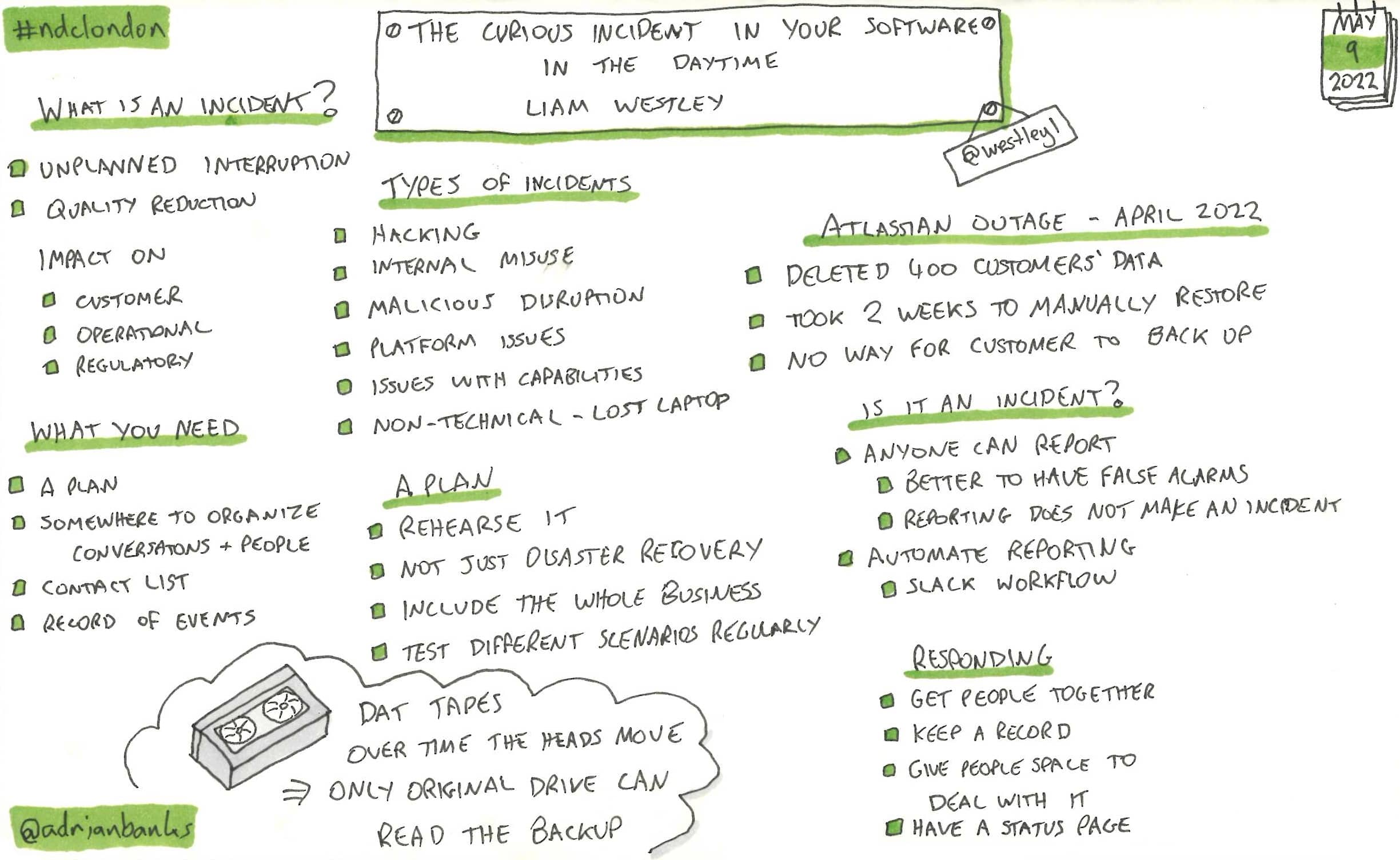
Liam discussed how to deal with incidents that happen with your software. He covered the kind of things that you should consider having in place to deal win an incident, and showed some example incidents and how they were dealt with. One thing that stood out from the examples was that having extensive detailed logging helps to inform about what has happened, and what data is affected. He also discussed points of failure that many people wouldn’t even consider, such as Slack being down or maxing out a credit card that is needed to pay for more resources.
The Untruthful Art - Five Ways Of Misrepresenting Data
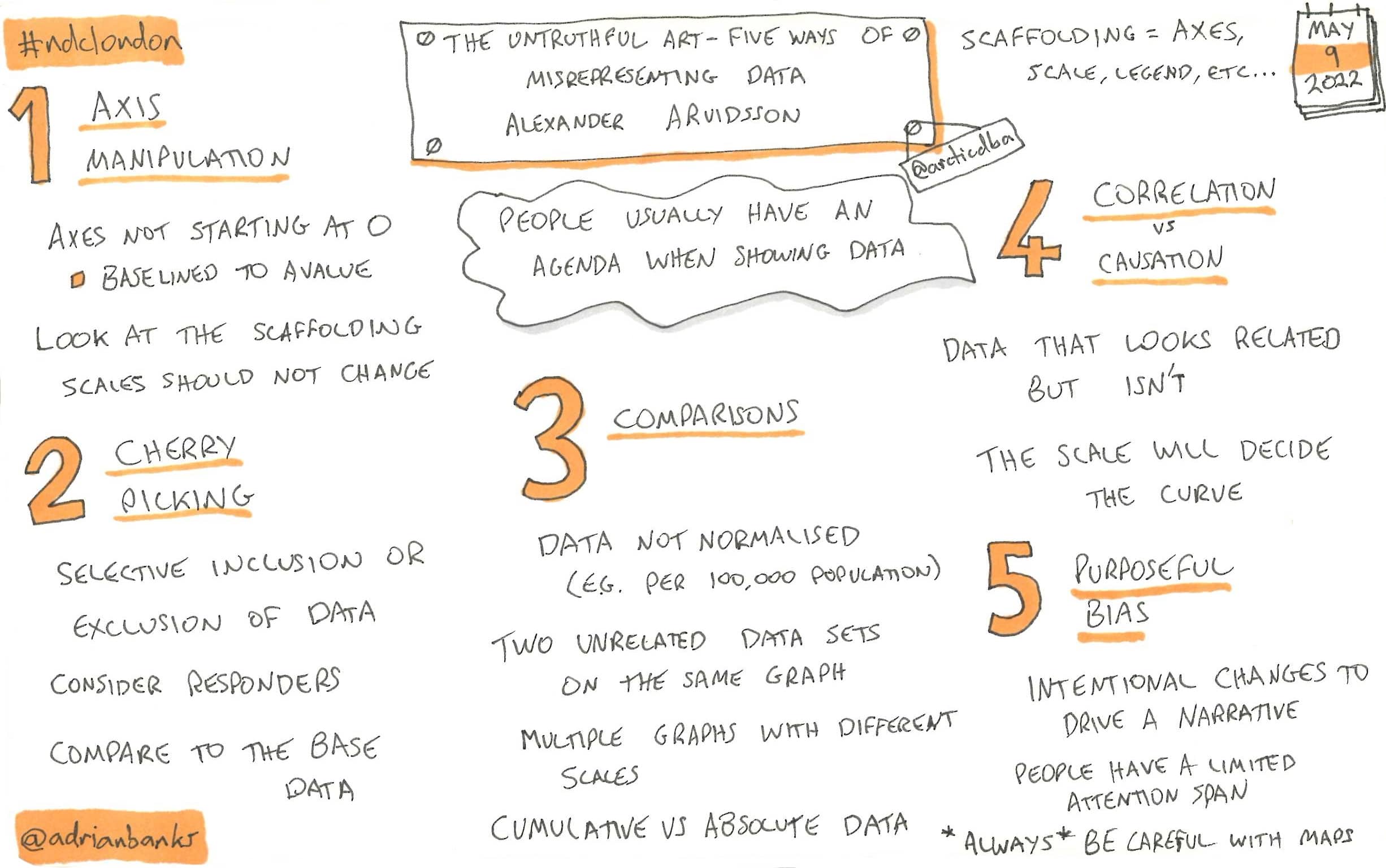
Alexander used many humourous examples to demonstrate how data can be displayed, or even manipulated, to give an incorrect representation. He also stressed the importance of considering any agenda that the author may have when creating the visualisations.
Wearable Live Captions
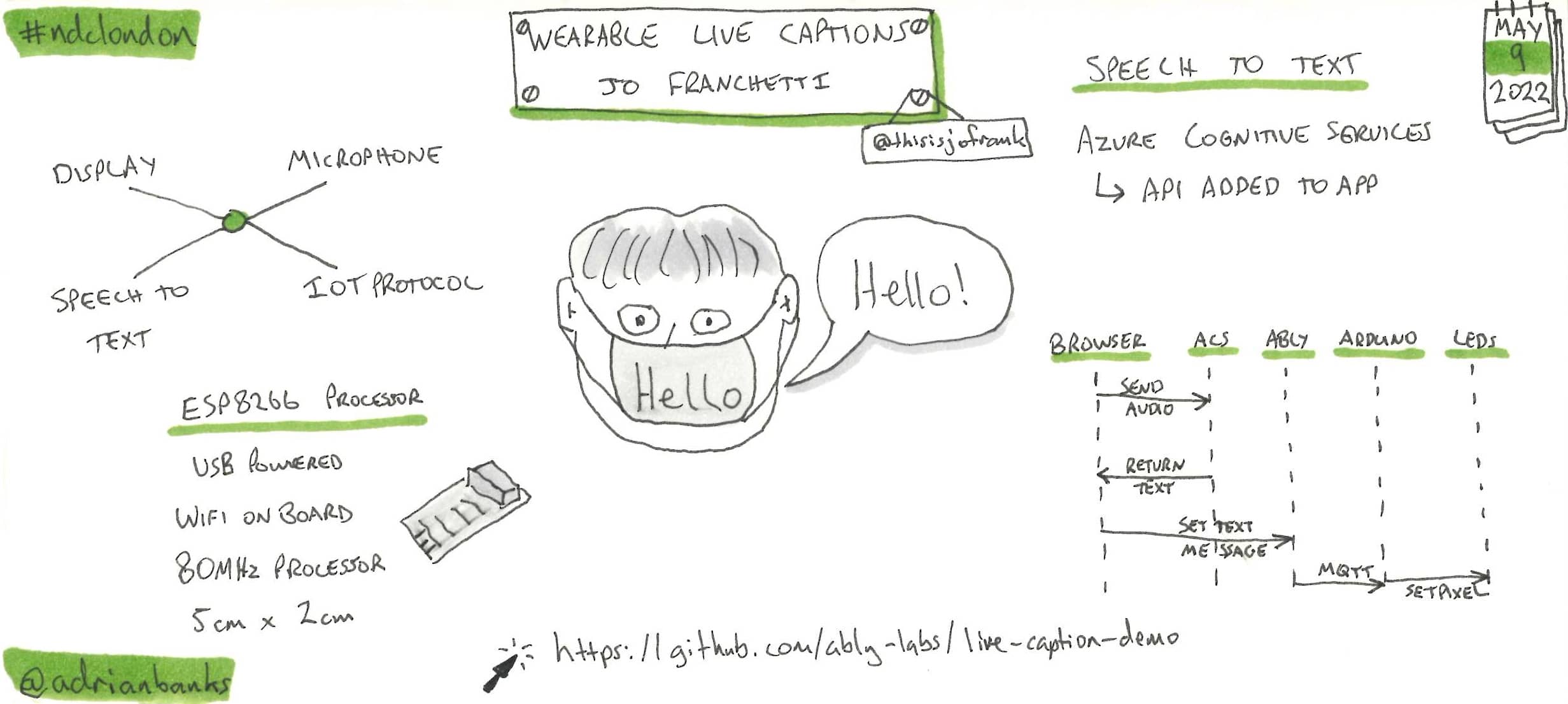
Jo demonstrated her live captioning face mask - a wearable face mask that she built to enable her deaf mother to read what she was saying while looking at her. Traditional captioning technology relies on reading what the speaker is saying from the phone screen, making it diffuclt to look at someone when they are speaking. This is different in that the phone uses Azure Cognitive Services to convert the speech to text, and then sends the text to and LED panel in the face mask via bluetooth.
The Visible Developer
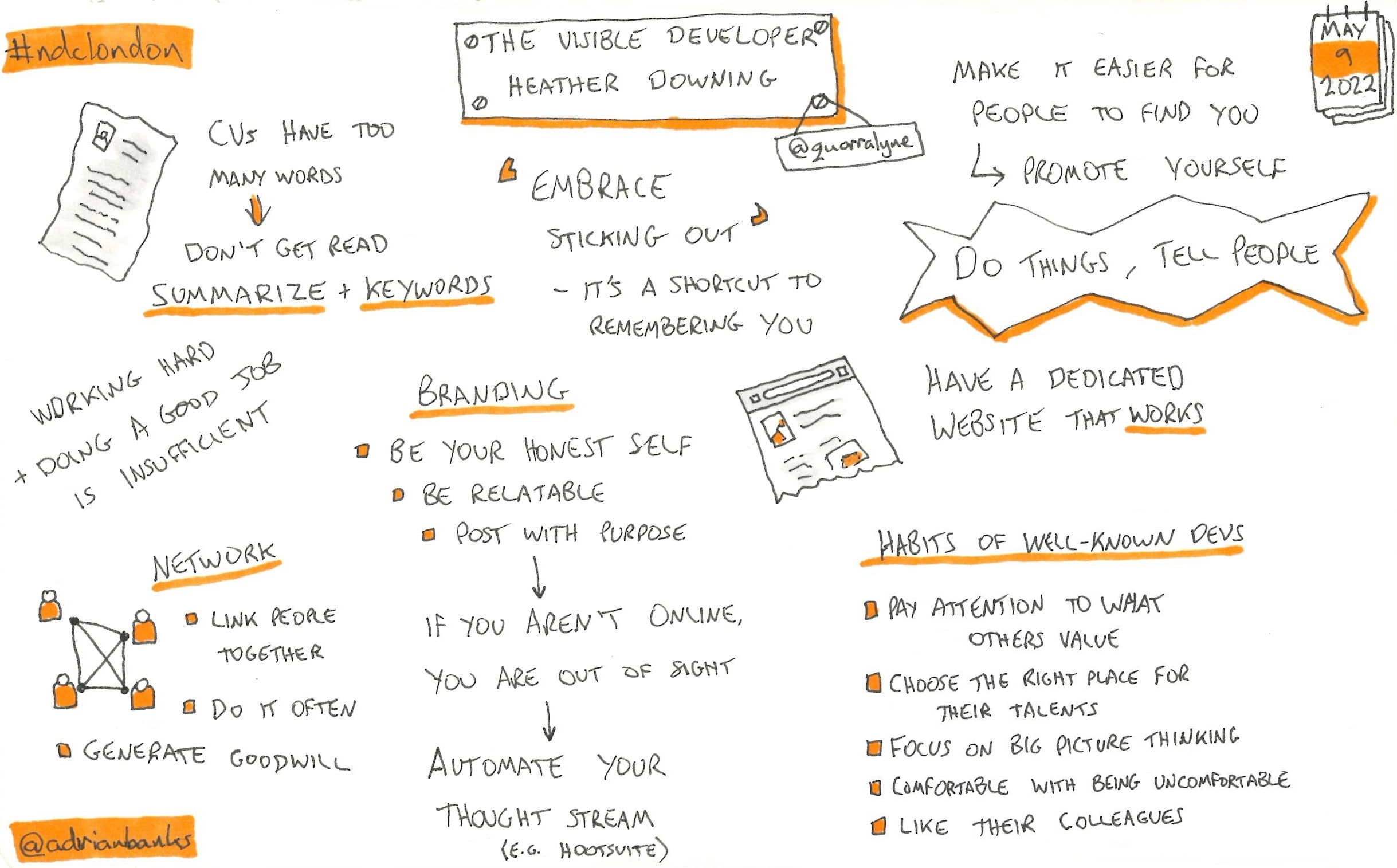
This talk was all about having a “developer brand”. Life isn’t fair, and it isn’t sufficient to work hard and be a good developer. If you do only that, you will not get recognition for your achievements. Heather encouraged people to make sure that other people know what you have done, and talked about several ways of doing this.
Roslyn Source Generators
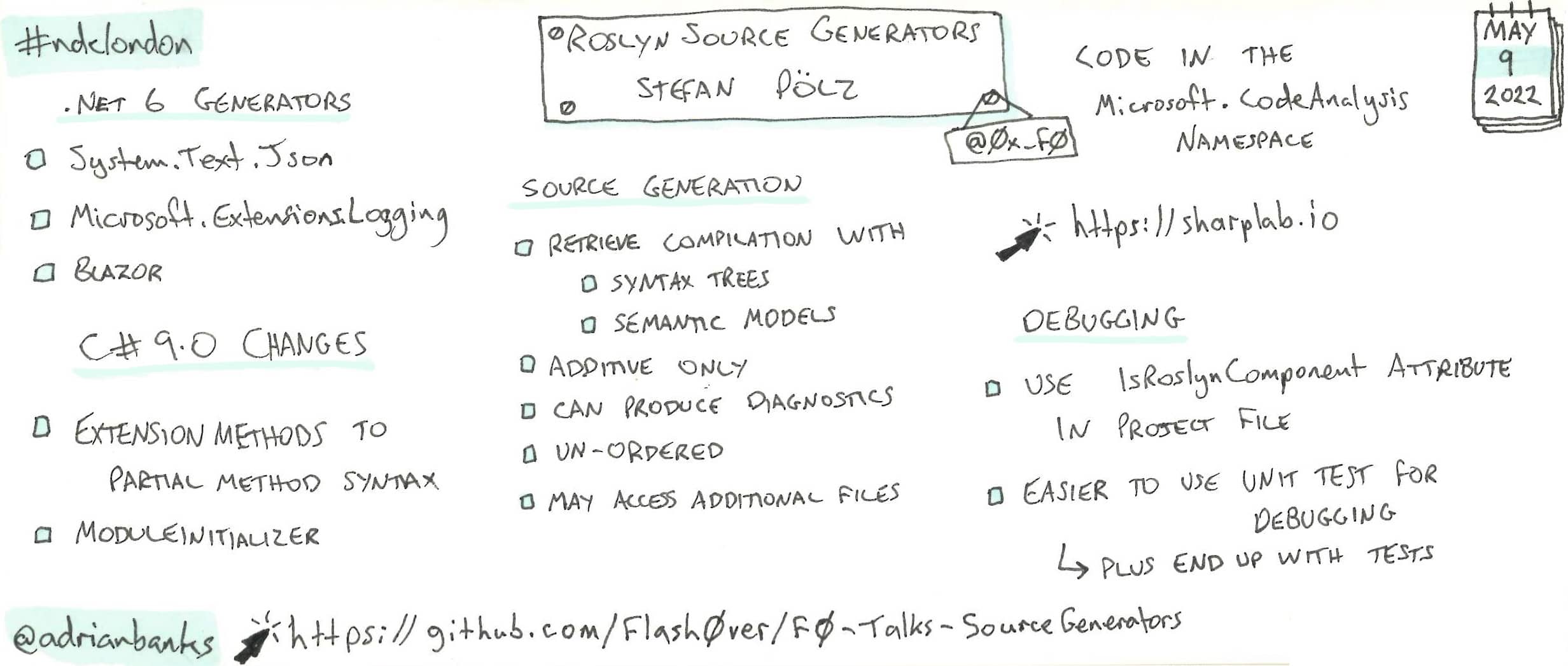
Stefan went through several uses for Roslyn source generators, and how to use them.
How The Fastest Growing Companies Develop Their Public API
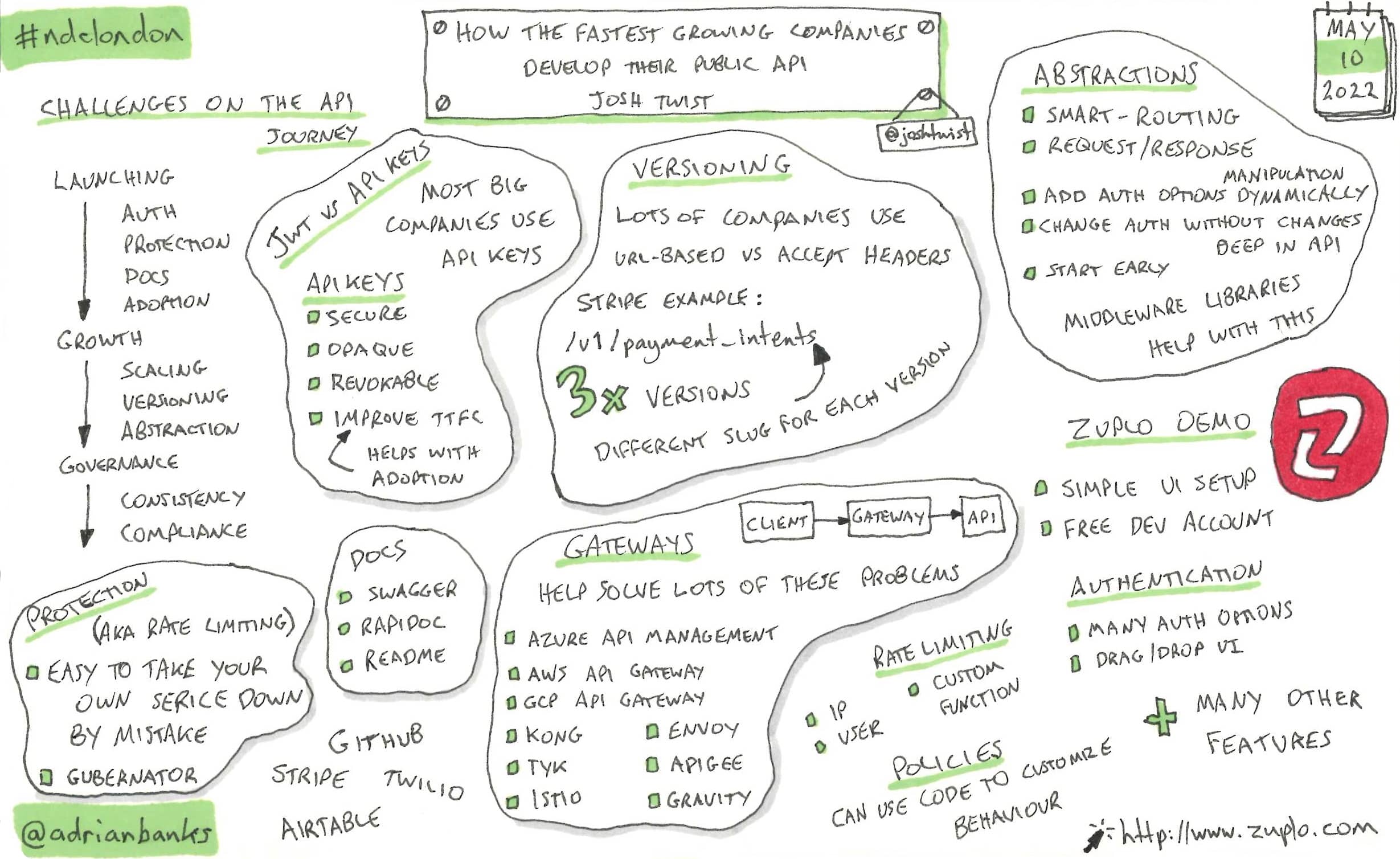
This talk was about making a public API on the web. Josh covered several of the key things that need to be considered when making a public API, and presented some possible solutions. One common solution for all of the considerations was an API gateway. He then demoed the Zuplo API gateway, something that Josh created after working at companies like Microsoft, Facebook, and Stripe.
Design For Developers
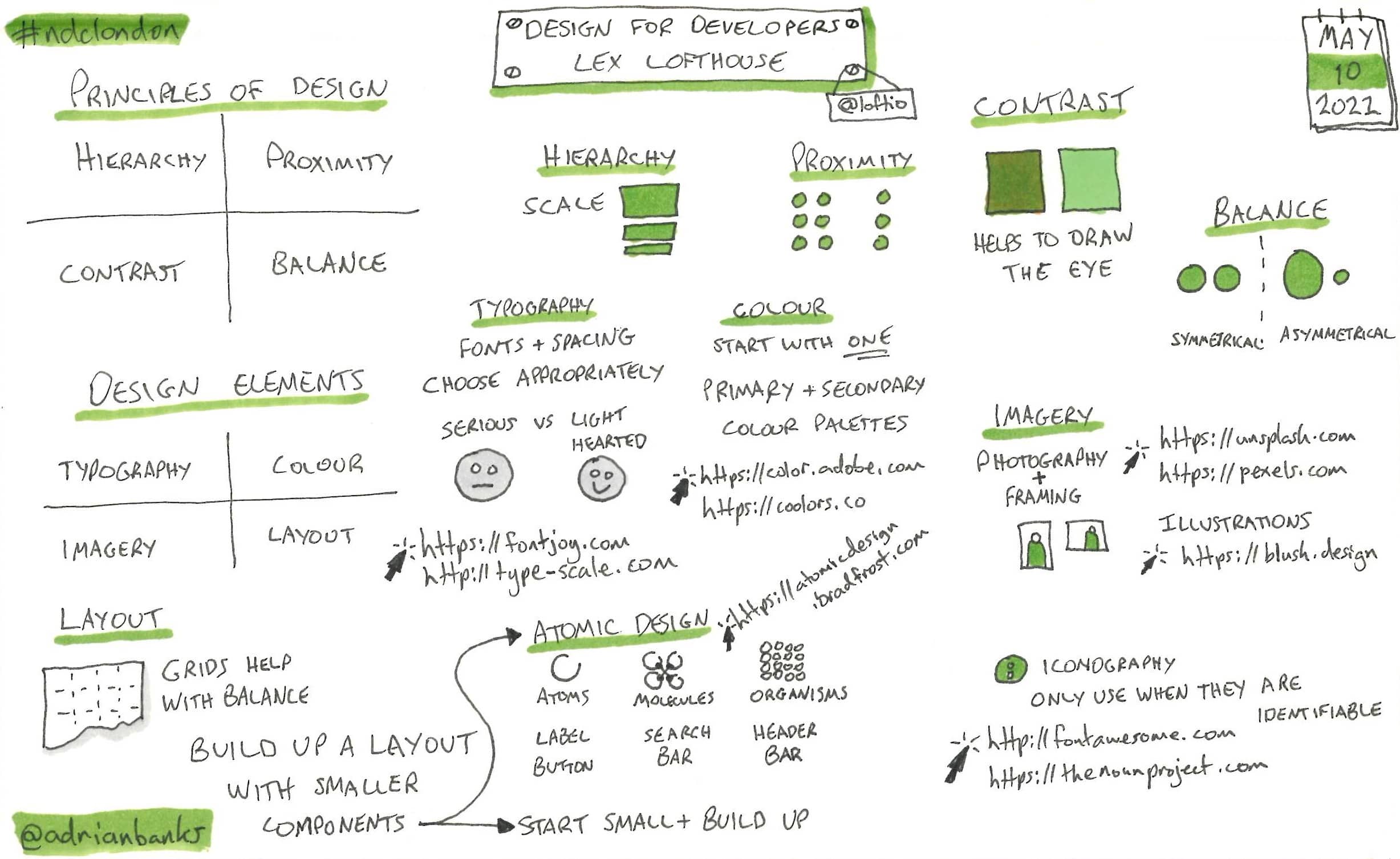
Lex covered several of the core design principles and theories for presenting content, with lots of resources to draw from for example content.
Tracking Database Changes With Apache Kafka
![]()
This talk covered how Apache Kafka can be used to track changes to a relational database. Francesco used a worked exampled to decouple a production transactional database from other potential uses such as data analysis and reporting, using Kafka log streaming to synchronise the data into a separate data store. He then introduced Debezium to track changes to a database without the need for polling.
Failure Is Always An Option
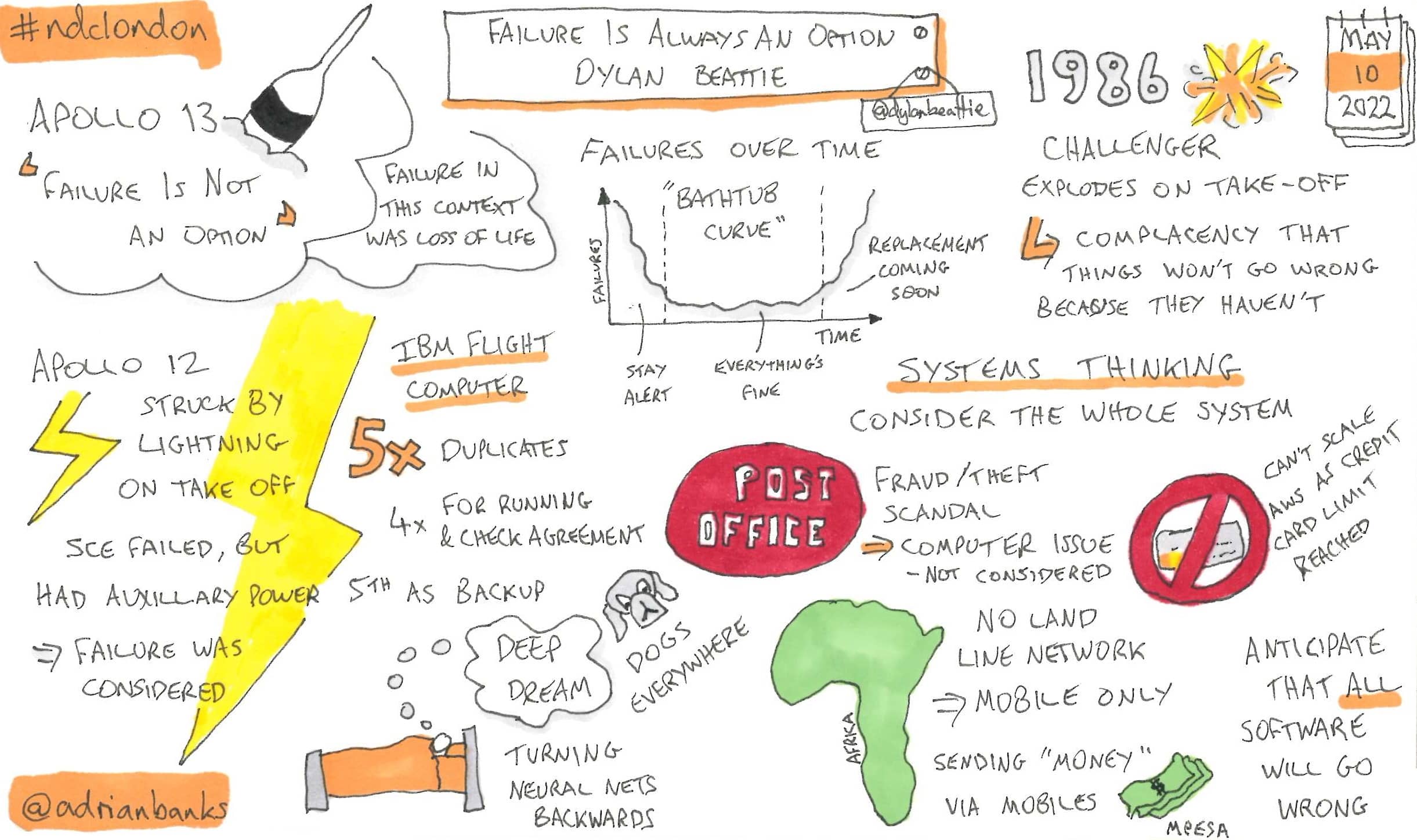
Dylan using the famous “failure is not an option” quote from Apollo 13 as inspiratino to highlight how we should always consider failure as an option in software systems, with examples from history of how failure modes were anticipated and came to be needed later.
Nevermind The Containers
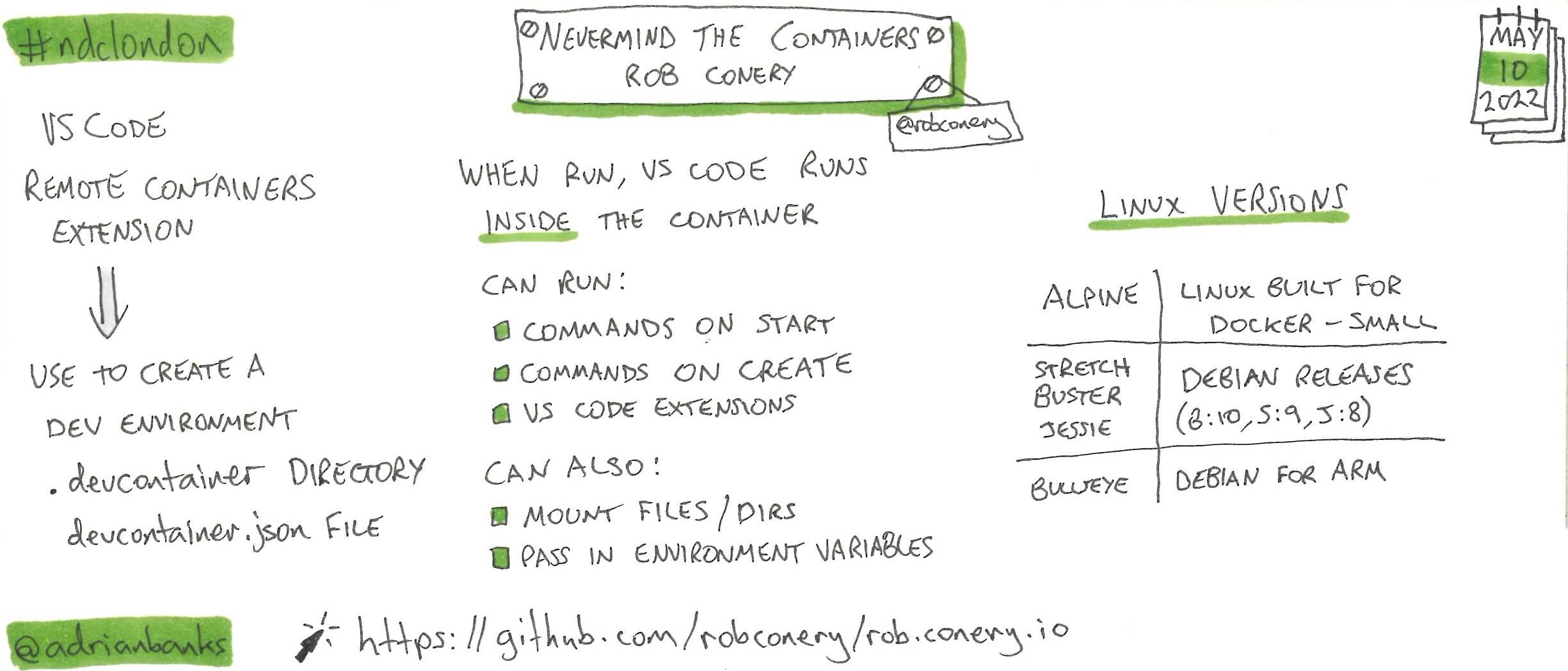
This talk was centred around the Remote Containers Visual Studio Code extension from Microsoft. This extension allows the configuration of a development environment using a devcontainer.json file, which when run with the extension spins up a Docker container with VS Code running inside it, with the UI running on the host machine. Rob did a very slick demo of how to set it up and use it using his Ruby-based blog as an example.
Fractal Architecture
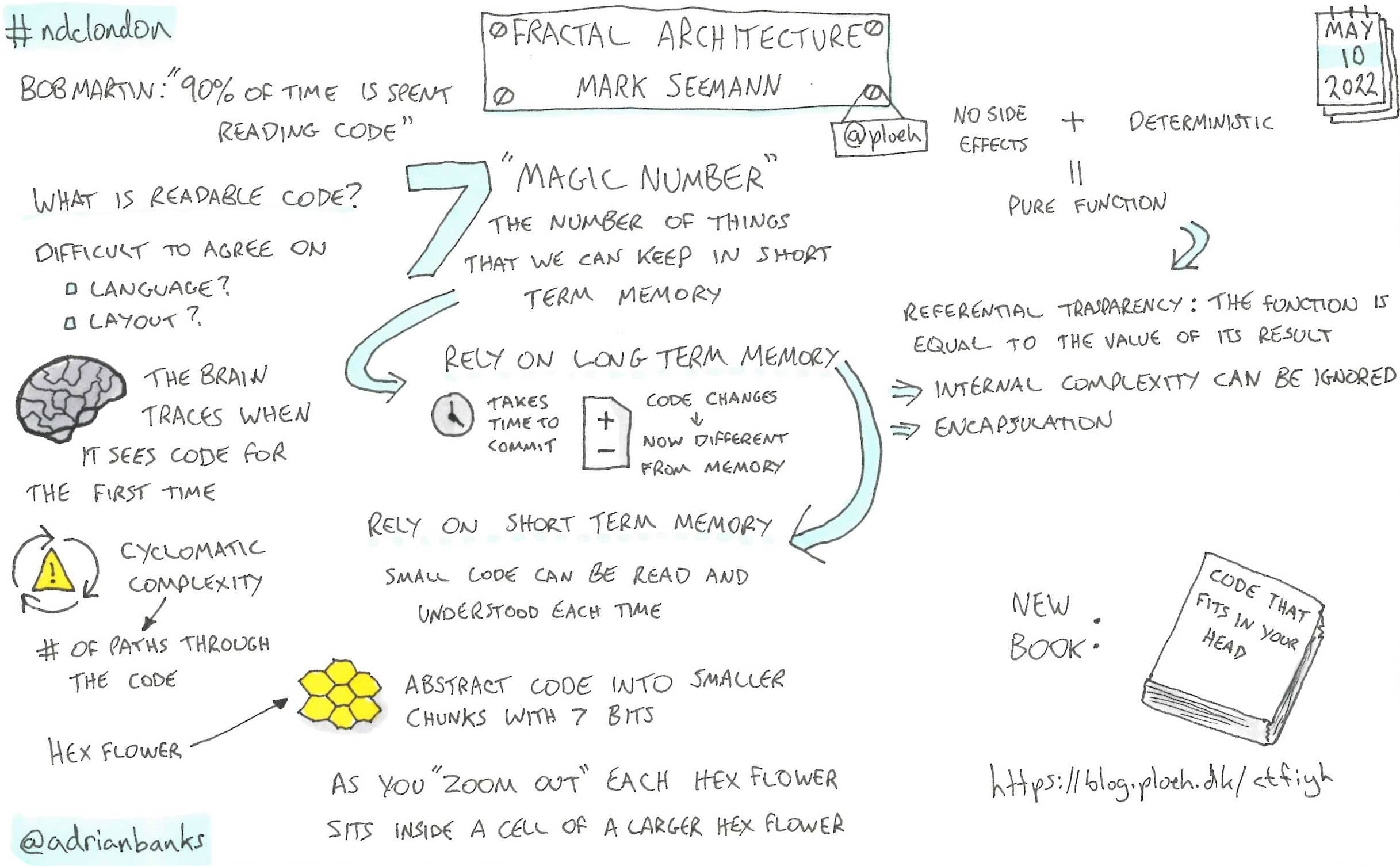
Mark talked through his latest thinking on developing easy to maintain code, which he has captured in his latest book. Using theroies about the human memory and its limitations, he introduced the concept of a “hex flower” to represent the 7 elements that fit in your head when reading code. By breaking code down into small enough parts to fit into these shapes, it allows a software system to be seen as being composed of hierarchies of these systems that fit together to abstract behaviour.
Software Lessons From Aviation Disasters
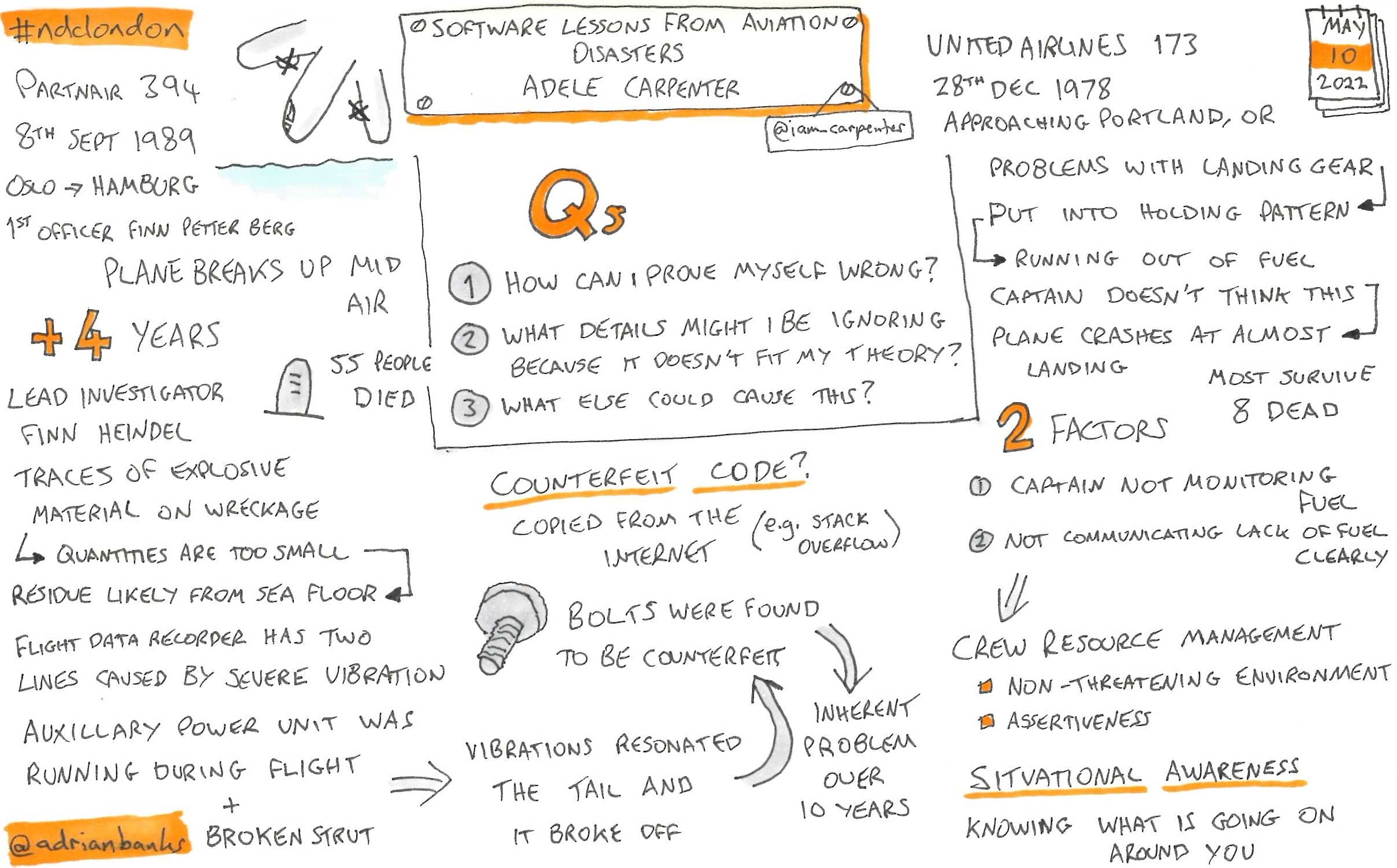
Adele talked through two examples of flights that went wrong, and linked them to their underlying causes. She compared these to the world of software as things to look out for.
Team Topologies, Software Architecture And Complexity Science
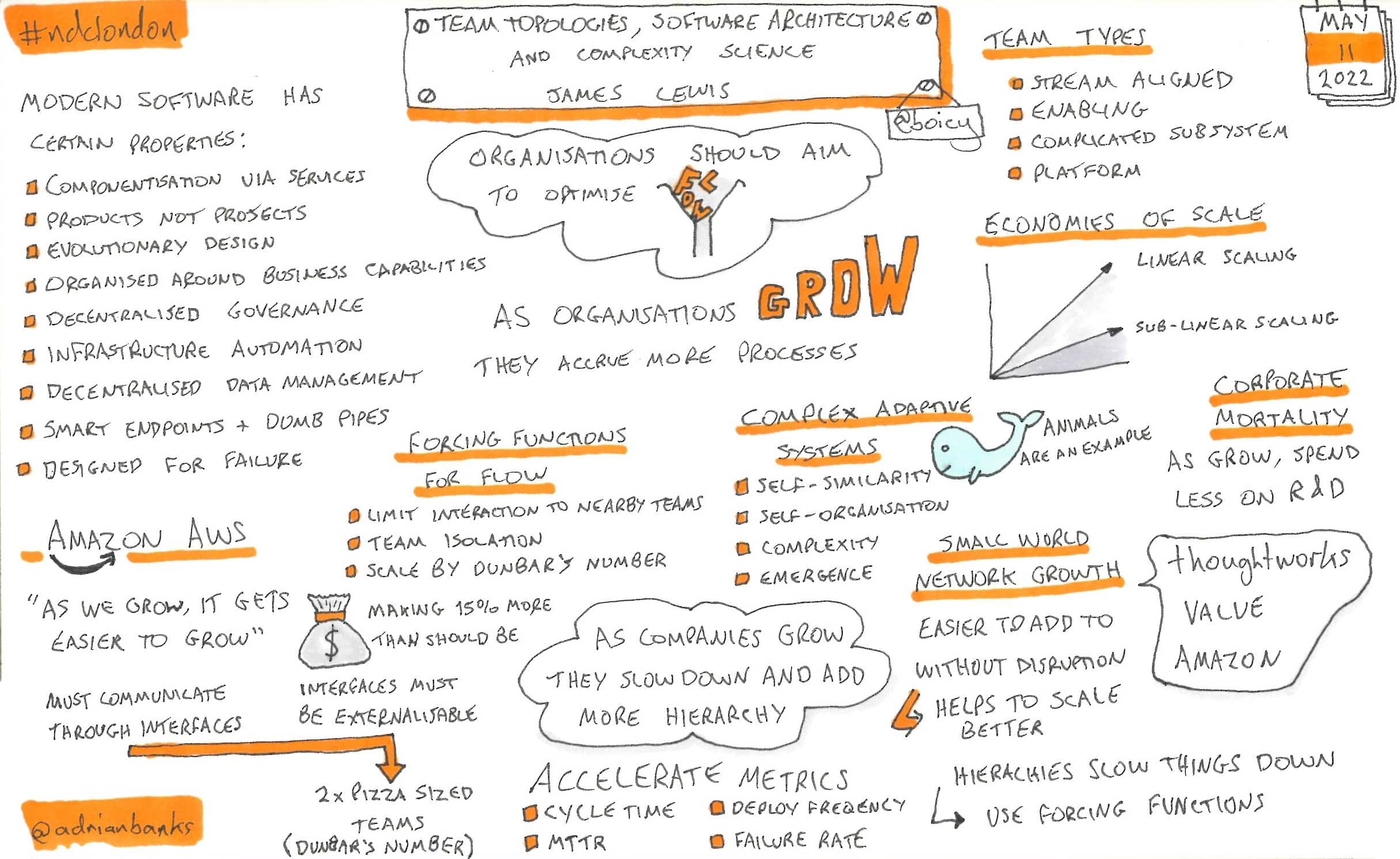
James talked about how most software companies get slower as they grow due to an ever-increasing number of processes and levels of hierarchy, and compared them to Amazon who are quoted as saying “the bigger we get, the easier it becomes to get bigger”. He then went through some of the reasons as to why Amazon can achieve this, with analogies drawn from city planning and biology.
Marvels Of Teenage Engineering
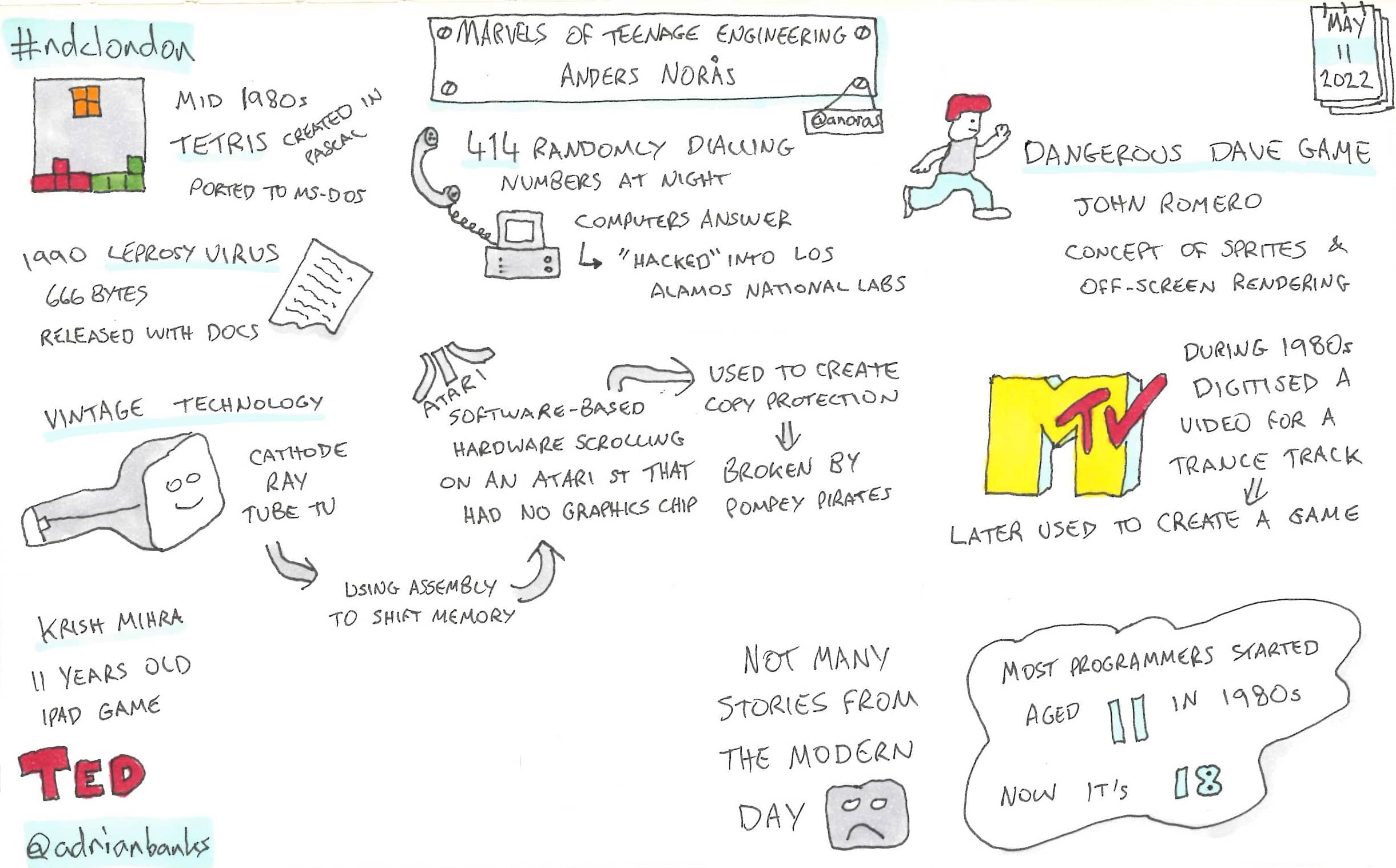
Anders took a nostalgic look back through development over the past forty years to highlight how the early developers honed their skills, and how seeming impossible things were achieved through perserverance and experimentation. He then lamented about how that is no longer the case as modern developers typically start coding much later in life, and don’t hone the curiosity that they would have if they were to start younger.
I’m Gonna Make You Stop Hating CSS
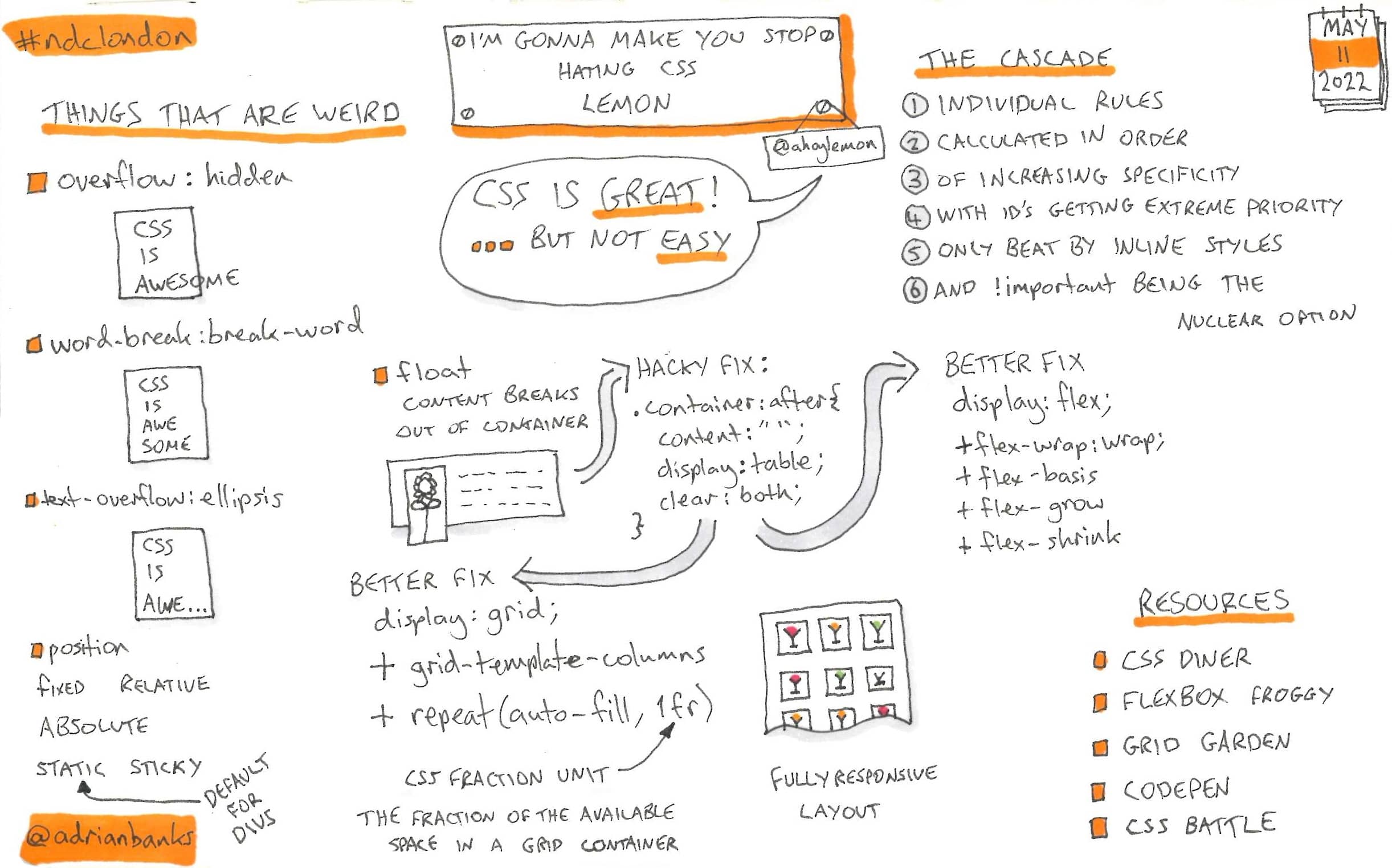
Lemon showed some things that CSS does poorly, such as the CSS is awesome meme, how people tend to fix them, and how to fix them in very simple ways, some of which required only a single line of CSS.
How To Close The Diversity Gap

Heather talked about the diversity gap in the majority of tech companies, and some of the things that can be done to reduce it. She used many examples from the WeCrashed and Super Pumped Tv series to demonstrate the issues.
ASP.NET Core Beyond The Basics
Chris did a talk consisting of 100% code (hence the lack of a sketchnote), showing how to do some of the more advanced things with ASP.NET Core. These included:
- Writing custom middleware
- Using distributed caching
- The
IActionConstraintinterface - Using custom output formatters
- Custom model binding
- Background tasks
- Configuring an app from an external assembly using IStartupFilter and IHostingStartup
He also used the Insomnia API client during his demos, which looked like a more lightweight version of Postman.